
O DeepFloyd IF é um modelo de texto para imagem que lida particularmente bem com texto e é basicamente uma versão de código aberto do Imagen do Google.
Em maio de 2022, o Google demonstrou o Imagen, um modelo de texto para imagem que superou o DALL-E 2 da OpenAI, que acabara de ser lançado na época. De acordo com a equipe e os exemplos mostrados, o modelo superou o DALL-E em precisão e qualidade da síntese de texto para imagem. Ele também foi capaz de gerar texto em imagens, uma capacidade que nenhum modelo de código aberto foi capaz de fazer de forma confiável.
Tal como acontece com outros modelos de IA geradores, como Stable Diffusion ou DALL-E 2, a equipe do Google contou com um codificador de texto congelado que converte prompts de texto em incorporações, que são então decodificadas em uma imagem por um modelo de difusão. Ao contrário de outros modelos, no entanto, o Imagen não usa o CLIPE multimodalmente treinado, mas sim o grande modelo de linguagem T5-XXL. A equipe conseguiu até mostrar que a qualidade das imagens geradas aumenta mais com o tamanho do modelo de linguagem do que com o treinamento do modelo de difusão, que é realmente responsável pela síntese de imagens.
O DeepFloyd IF é um Imagen de código aberto
Agora, a equipe da DeepFloyd, afiliada à StabilityAI, replicou essa arquitetura e lançou uma espécie de imagem de código aberto chamada IF. De acordo com a equipe, o IF demonstra a alta qualidade de imagem e as capacidades de compreensão da linguagem do Imagen. Ele foi treinado com cerca de 1,2 bilhão de imagens do conjunto de dados LAION-5B.
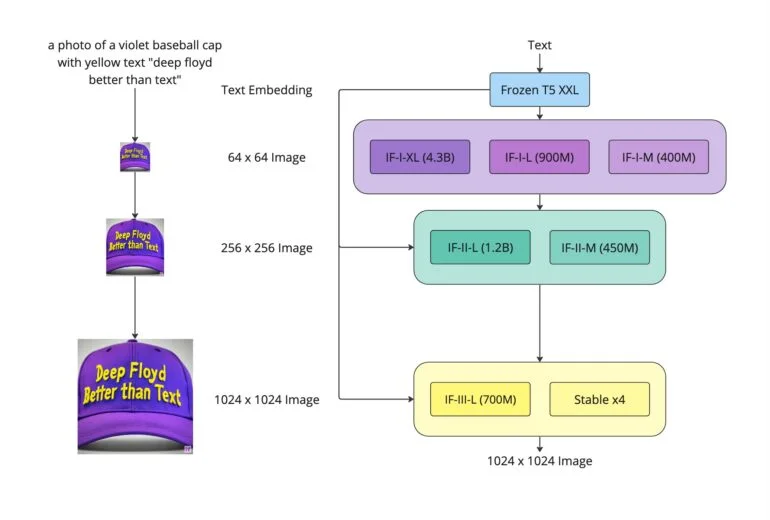
Em testes, ele ainda supera o Google Imagen, alcançando uma pontuação FID Zero-Shot de 6,66 no conjunto de dados COCO, também à frente de outros modelos disponíveis, como o Stable Diffusion.




De acordo com a equipe, o IF também suporta Image-to-Image-Translation e Impainting.
Como o Imagen, o DeepFloyd IF conta com dois modelos de super-resolução que elevam a resolução das imagens para 1.024 x 1.024 pixels e oferece diferentes tamanhos de modelo com até 4,3 bilhões de parâmetros. Para o maior modelo com um upscaler de 1.024 pixels, a equipe recomenda 24 gigabytes de VRAM, enquanto o maior modelo com um upscaler de 256 pixels ainda requer 16 gigabytes de VRAM.
DeepFloyd mostra o próximo nível de síntese de texto para imagem
De acordo com a DeepFloyd, o trabalho mostra o potencial de arquiteturas UNet maiores no primeiro estágio de modelos de difusão em cascata e, portanto, um futuro promissor para a síntese de texto para imagem. Em outras palavras, o IF da DeepFloyd mostra claramente que a IA gerativa pode ficar ainda melhor e que a comunidade de código aberto poderia alcançar modelos como o Parti do Google no futuro, o que supera o Imagen em alguns aspectos.
A primeira versão do modelo IF está sujeita a uma licença restrita, destinada apenas a fins de pesquisa – ou seja, fins não comerciais – para coletar temporariamente feedback. Depois que esse feedback for coletado, a equipe da DeepFloyd e da StabilityAI lançará uma versão comercialmente compatível totalmente gratuita.
O IF da DeepFloyd tem um Github, uma demonstração está disponível no HuggingFace. Mais informações estão disponíveis no site da DeepFloyd.
