
Jusqu’à présent, il n’existait pas de moyen simple de comparer la qualité des modèles open source. Un système inspiré des sports électroniques pourrait y contribuer.
La Large Model System Organisation (LMSYS), responsable du modèle open source Vicuna, a lancé la plateforme de référence « Chatbot Arena » pour comparer les performances des grands modèles de langage. Différents modèles s’affrontent dans des duels anonymes choisis au hasard. Les utilisateurs évaluent ensuite les performances des modèles en votant pour leurs réponses préférées.
Sur la base de ces évaluations, les modèles sont classés selon le système de notation Elo, largement utilisé aux échecs et surtout dans les sports électroniques. En principe, les utilisateurs peuvent poser n’importe quelle question et même avoir de longues conversations, mais ils ne peuvent pas demander directement le nom du modèle, car cela disqualifie leur vote pour l’évaluation.
Le GPT-4 obtient le meilleur Elo, mais Claude le suit de près
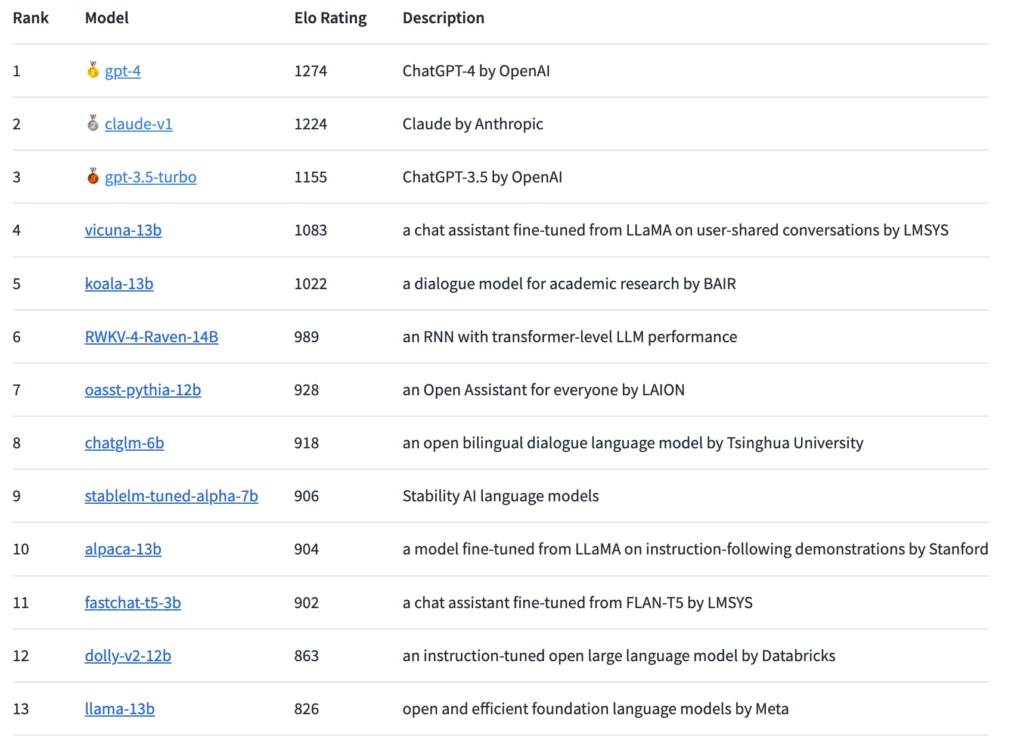
Selon cette méthode, le GPT-4 est actuellement en tête du classement, suivi de près par le Claude-v1 et le GPT-3.5-turbo avec un écart légèrement plus important. Le modèle open source le mieux classé est le Vicuna-13B. À l’avenir, les chercheurs prévoient d’intégrer un plus grand nombre de modèles à source ouverte et fermée et d’établir un classement plus précis.
Depuis la fuite du modèle linguistique LLaMA de Meta, plusieurs modèles linguistiques open source ont vu le jour qui, comme ChatGPT, sont conçus pour suivre des instructions humaines et répondre aux questions des utilisateurs d’une manière similaire à celle d’un chatbot. Cependant, la difficulté réside dans l’évaluation efficace de ces modèles, en particulier pour les questions ouvertes.
L’entrée en scène de Chatbot Arena
Chatbot Arena offre une approche prometteuse. Le système Elo d’évaluation des grands modèles de langage a déjà été utilisé par Anthropic pour l’évaluation de Claude.
Dans l’arène, les modèles s’affrontent directement et les utilisateurs votent pour le meilleur modèle en interagissant avec lui. La plateforme recueille toutes les interactions des utilisateurs, mais n’utilise que les votes exprimés avec les noms des modèles inconnus. Selon LMSYS, environ 4 700 votes anonymes valides ont été reçus une semaine après le lancement, et au début du mois de mai, ce nombre était passé à environ 13 000.
Les résultats obtenus jusqu’à présent montrent un « écart substantiel » entre les modèles propriétaires et les modèles libres, selon LMSYS. Cependant, les modèles open source représentés dans l’arène avaient également beaucoup moins de paramètres, allant de trois à 14 milliards. Sans compter les matchs nuls, le GPT-4 remporte 82 % des duels contre le Vicuna-13B et 79 % des duels contre le GPT-3.5-turbo. Le Claude d’Anthropic bat le GPT-3.5 dans l’arène et fait jeu égal avec le GPT-4.
Outre la compétition dans l’arène, le mode Side by Side est particulièrement pratique : vous pouvez sélectionner des modèles linguistiques open source individuels et leur envoyer le même stimulus en même temps. Les résultats peuvent être comparés en temps réel.
Accédez à la Chatbot Arena si vous souhaitez participer au vote ou trouver un modèle de langage open source qui vous soit utile. La plateforme Playground de Nathaniel Friedman, ancien PDG de GitHub, fonctionne de manière similaire.

