
O BLIVA é um modelo de linguagem visual que se destaca na leitura de texto em imagens, tornando-se útil em cenários e aplicações do mundo real em várias indústrias.
Pesquisadores da UC San Diego desenvolveram o BLIVA, um modelo de linguagem visual projetado para lidar melhor com imagens que contêm texto. Modelos de linguagem visual (VLMs) estendem os modelos de linguagem grandes (LLMs) incorporando capacidades de compreensão visual para responder a perguntas sobre imagens.
Esses modelos multimodais têm feito progressos impressionantes em benchmarks de perguntas e respostas visuais abertas. Um exemplo é o GPT-4 da OpenAI, que em sua forma multimodal pode discutir o conteúdo da imagem quando solicitado por um usuário, embora essa capacidade atualmente só esteja disponível no aplicativo “Be My Eyes”.
No entanto, uma grande limitação dos sistemas atuais é a capacidade de lidar com imagens que contenham texto, o que é comum em cenários do mundo real.
O BLIVA combina InstructBLIP e LLaVA
Para abordar esse problema, a equipe desenvolveu o BLIVA, que significa “BLIP com Assistente Visual”. O BLIVA incorpora dois tipos complementares de incorporações visuais, ou seja, incorporações de consulta aprendidas extraídas por um módulo Q-former para se concentrar em regiões da imagem relevantes para a entrada textual, semelhante ao Salesforce InstructBLIP, e incorporações de remendos codificados extraídas diretamente dos remendos de pixels brutos da imagem completa, inspiradas no LLaVA da Microsoft (Assistente de Linguagem e Visão de Grande Escala).
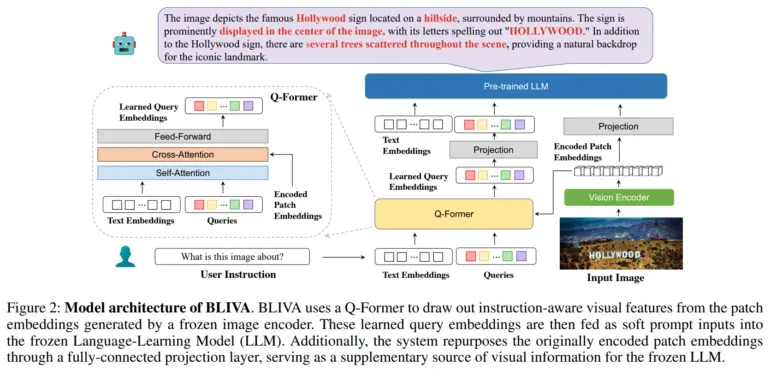
Segundo os pesquisadores, essa abordagem dupla permite ao BLIVA usar tanto incorporações refinadas baseadas em consultas adaptadas ao texto quanto incorporações de remendos mais ricos que capturam mais detalhes visuais.
O BLIVA é pré-treinado com aproximadamente 550.000 pares de imagens e legendas, e foi ajustado com 150.000 exemplos de perguntas e respostas visuais, mantendo o codificador visual e o modelo de linguagem congelados.
A equipe demonstrou que o BLIVA melhora significativamente o tratamento de imagens ricas em texto em conjuntos de dados como OCR-VQA, TextVQA e ST-VQA. Por exemplo, alcançou uma precisão de 65,38% no OCR-VQA, em comparação com 47,62% para o InstructBLIP. O novo sistema também superou o InstructBLIP em sete dos oito benchmarks gerais de perguntas e respostas visuais que não envolvem texto. A equipe acredita que isso demonstra os benefícios das abordagens de múltiplas incorporações para a compreensão visual em geral.

Os pesquisadores também avaliaram o BLIVA em um novo conjunto de dados de miniaturas de vídeos do YouTube com perguntas associadas, disponíveis no Hugging Face. O BLIVA alcançou uma precisão de 92%, significativamente superior aos métodos anteriores. A capacidade do BLIVA de ler texto em imagens, como placas de trânsito ou embalagens de alimentos, poderia permitir aplicações práticas em diversas indústrias, afirmou a equipe. Recentemente, pesquisadores da Microsoft demonstraram um assistente de IA multimodal para biomedicina baseado no LLaVA, chamado LLaVA-med.
Mais informações e o código estão disponíveis no Github do BLIVA, e uma demonstração está disponível no Hugging Face.
