
Benchmark revela que agentes de IA ainda não conseguem substituir analistas humanos na área financeira
Apesar do acesso a ferramentas de pesquisa e dos elevados custos de processamento, os principais modelos de linguagem apresentaram resultados insatisfatórios em tarefas financeiras complexas.
Um novo benchmark da Vals.ai sugere que, mesmo os agentes autônomos de IA mais avançados continuam pouco confiáveis para análises financeiras. O modelo com melhor desempenho, o o3 da OpenAI, obteve apenas 48,3% de acurácia – com um custo médio de US$ 3,69 por consulta.
O benchmark foi desenvolvido em colaboração com um laboratório de Stanford e um banco global de importância sistêmica e consiste em 537 tarefas baseadas nas responsabilidades reais de analistas financeiros, como análise de documentos da SEC, pesquisa de mercado e projeções. Ao todo, 22 modelos de base foram avaliados.

A pontuação de “Acurácia” no benchmark da Vals.ai reflete a porcentagem de tarefas concluídas corretamente por cada modelo. O teste abrange conhecimentos factuais, uso de ferramentas de pesquisa e raciocínio financeiro.
Tarefas básicas apresentam potencial, mas o raciocínio financeiro complexas ainda estão fora do alcance
Os modelos demonstraram sucesso limitado em tarefas básicas, como extrair dados numéricos ou resumir textos – com acurácia média variando de 30% a 38%. Entretanto, eles fracassaram em tarefas mais complexas. Na categoria “Tendências”, dez modelos registraram 0%, com o melhor resultado – 28,6% – obtido pelo Claude 3.7 Sonnet.
Para executar essas tarefas, o ambiente do benchmark ofereceu aos agentes o acesso a ferramentas como a busca EDGAR, o Google e um analisador HTML. Modelos como o o3 da OpenAI e o Claude 3.7 Sonnet (Thinking), que utilizaram essas ferramentas com maior frequência, tiveram desempenho relativamente melhor. Em contrapartida, modelos como o Llama 4 Maverick frequentemente ignoraram o uso das ferramentas, produzindo resultados sem realizar pesquisas – o que se refletiu em desempenhos inferiores.
No entanto, o uso intensivo de ferramentas nem sempre se traduziu em melhor desempenho. O GPT-4o Mini, que mais acionou as ferramentas, ainda apresentou baixa acurácia devido a erros constantes na formatação e na sequência das tarefas. Já o Llama 4 Maverick costumava fornecer respostas sem a realização de buscas.
Em alguns casos, o processamento de uma única consulta ultrapassou os US$ 5. O modelo o1 da OpenAI se destacou como particularmente ineficiente: baixa acurácia e altos custos. Em aplicações práticas, essas despesas teriam que ser comparadas com o custo do trabalho humano.
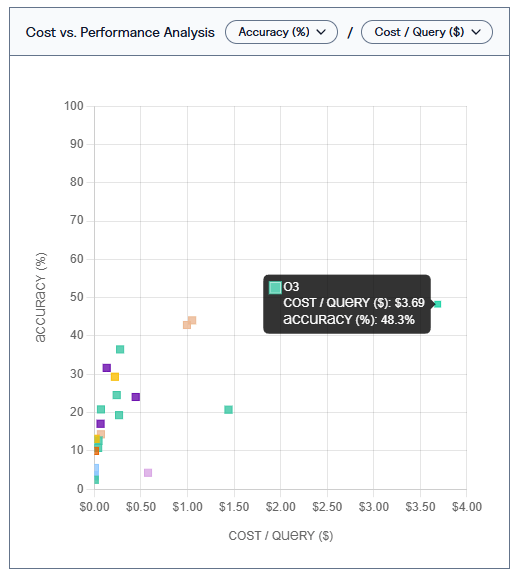
O modelo o3 da OpenAI liderou o benchmark com 48,3% de acurácia, mas também apresentou o custo mais alto por consulta, de US$ 3,69. O Claude 3.7 Sonnet apresentou desempenho semelhante – entre 43% e 44% de acurácia – com apenas US$ 1 por consulta. Por sua vez, o o1 da OpenAI teve a pior relação custo-desempenho: US$ 1,50 por consulta para cerca de 20% de acurácia.
O desempenho dos modelos variou consideravelmente. Em uma tarefa focada nos recomprados de ações da Netflix no quarto trimestre de 2024, o Claude 3.7 Sonnet (Thinking) e o Gemini 2.5 Pro forneceram respostas precisas e com fontes confiáveis. Por outro lado, o GPT-4o e o Llama 3.3 ou não localizaram as informações relevantes ou forneceram respostas incorretas. Essas inconsistências ressaltam a necessidade contínua de supervisão humana em áreas como engenharia de prompts, configuração do sistema e avaliação interna.
Um abismo marcante entre investimento e prontidão para o mundo real
A Vals.ai conclui que os agentes de IA de hoje são capazes de lidar com tarefas simples, embora demoradas, mas permanecem pouco confiáveis para uso em setores sensíveis e altamente regulamentados, como o financeiro. Os modelos ainda enfrentam dificuldades com tarefas complexas e repletas de contexto, não podendo, no momento, servir como base única para a tomada de decisões.
Embora os modelos consigam extrair dados básicos de documentos, eles falham quando é necessário um raciocínio financeiro aprofundado – tornando-os inadequados para substituir completamente os analistas humanos.
“Os dados revelam um abismo marcante entre investimento e prontidão. Os agentes atuais conseguem buscar números, mas tropeçam no crucial raciocínio financeiro necessário para realmente aprimorar o trabalho dos analistas e liberar valor neste setor,” segundo a declaração da empresa.
O framework do benchmark está disponível como código aberto via GitHub, embora o conjunto de dados de teste permaneça privado para evitar treinamentos direcionados. Uma análise detalhada dos resultados do benchmark também está disponível no site da Vals.ai.
