
Pesquisadores da Microsoft demonstram LLaVA-Med, um assistente de IA multimodal para biomedicina capaz de processar imagens e texto.
Um grande conjunto de dados de pares de imagem-texto biomédicos foi utilizado para treinar o modelo de IA multimodal. O conjunto de dados inclui radiografias de tórax, ressonância magnética, histologia, patologia e imagens de tomografia computadorizada, entre outras. Primeiramente, o modelo aprende a descrever o conteúdo dessas imagens e, assim, conceitos biomédicos importantes. Em seguida, o LLaVA-Med (Large Language and Vision Assistant for BioMedicine) é treinado com um conjunto de dados de instruções gerado pelo GPT-4.
Esse conjunto de dados é criado pelo GPT-4 com base nos textos biomédicos que contêm todas as informações sobre cada imagem e pode ser usado para gerar pares de perguntas e respostas sobre as imagens. Na fase de ajuste fino, o LLaVA-Med é então treinado nas imagens e nos exemplos correspondentes do GPT-4.
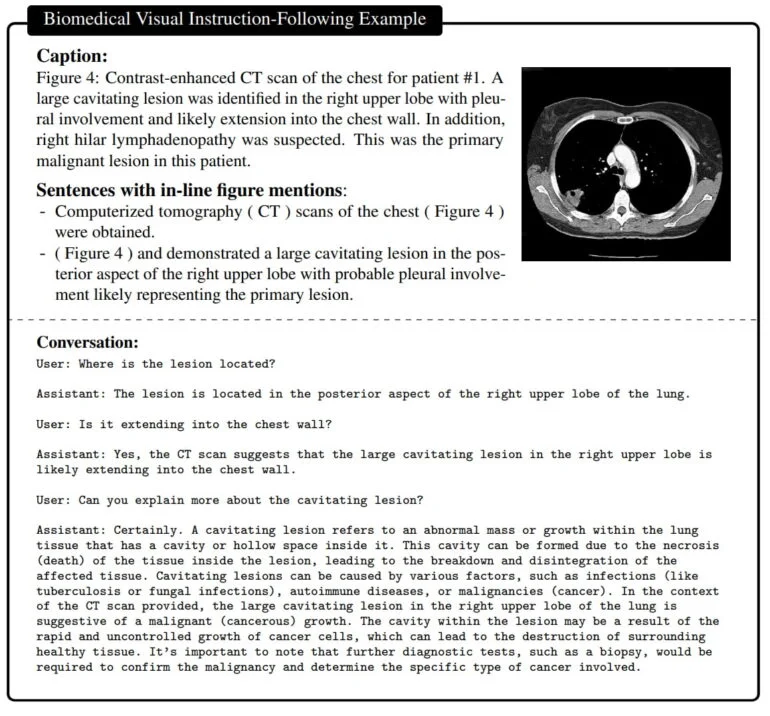
O resultado é um assistente capaz de responder a perguntas sobre uma imagem biomédica em linguagem natural.
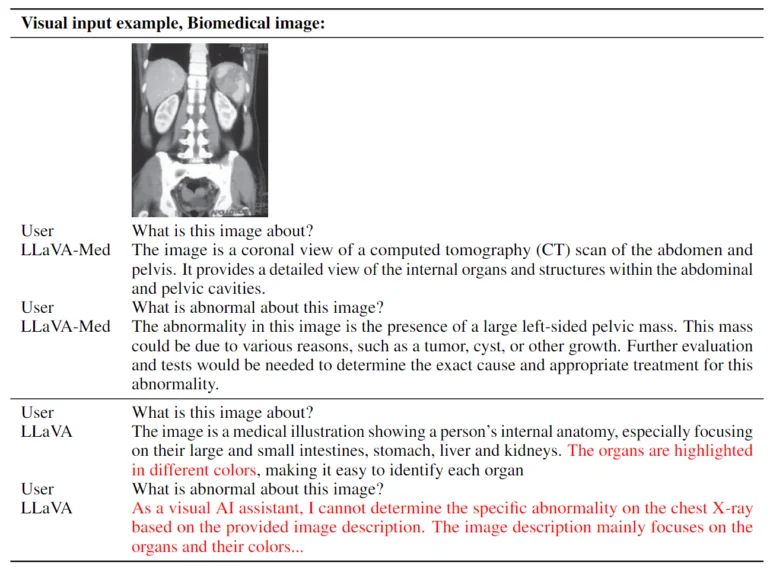
LLaVA-Med foi treinado em 15 horas
O método de treinamento utilizado permitiu que o LLaVA-Med fosse treinado em oito GPUs Nvidia A100 em menos de 15 horas. Ele é baseado em um Vision Transformer e no modelo de linguagem Vicuna, que por sua vez é baseado no LLaMA da Meta. De acordo com a equipe, o modelo possui “excelente capacidade de conversação multimodal”. Em três conjuntos de dados biomédicos padrão para responder a perguntas visuais, o LLaVA-Med superou modelos anteriores de última geração em algumas métricas.
Assistentes multimodais como o LLaVA-Med poderiam, um dia, ser utilizados em diversas aplicações biomédicas, como pesquisa médica, interpretação de imagens biomédicas complexas e suporte de conversação na área da saúde.
No entanto, a qualidade ainda não é boa o suficiente: “Embora acreditemos que o LLaVA-Med representa um passo significativo para a construção de um assistente visual biomédico útil, observamos que o LLaVA-Med é limitado por alucinações e um raciocínio profundo fraco comum a muitos LMMs”, diz a equipe. Trabalhos futuros se concentrarão em melhorar a qualidade e a confiabilidade.
Mais informações estão disponíveis no GitHub.
