
Até agora, não havia uma maneira fácil de comparar a qualidade de modelos de código aberto. Um sistema inspirado em e-sports poderia ajudar.
A Organização do Sistema de Modelos Grandes (LMSYS), responsável pelo modelo de código aberto Vicuna, lançou a plataforma de referência “Chatbot Arena” para comparar o desempenho de grandes modelos de linguagem. Diferentes modelos competem entre si em duelos anônimos e selecionados aleatoriamente. Os usuários, então, classificam o desempenho dos modelos votando em suas respostas preferidas.
Com base nessas classificações, os modelos são ranqueados de acordo com o sistema de classificação Elo, amplamente utilizado no xadrez e especialmente nos e-sports. Em princípio, os usuários podem fazer qualquer pergunta e até mesmo ter conversas longas, mas não podem solicitar diretamente o nome do modelo – isso desqualifica seu voto para a classificação.
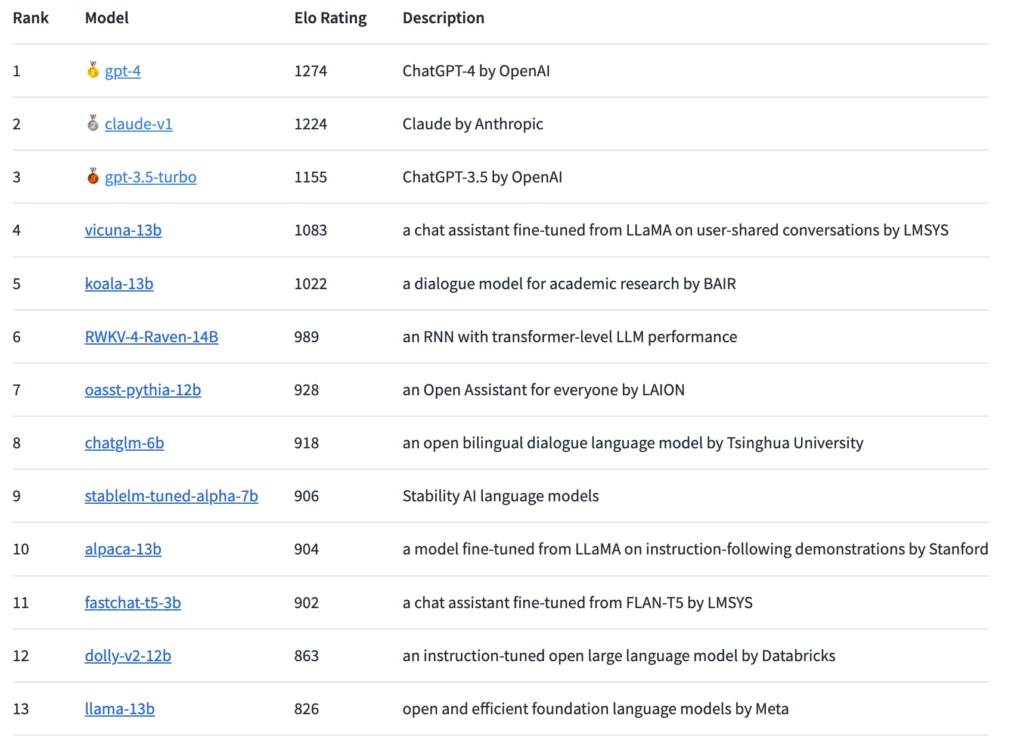
GPT-4 alcança o Elo mais alto, mas Claude está próximo
Usando esse método, o GPT-4 atualmente lidera o ranking, seguido de perto pelo Claude-v1 e o GPT-3.5-turbo com uma diferença um pouco maior. O modelo de código aberto com a classificação mais alta é o Vicuna-13B. No futuro, os pesquisadores planejam integrar mais modelos de código aberto e fechado e detalhar as classificações de forma mais precisa.
Desde o vazamento do modelo de linguagem LLaMA da Meta, surgiram diversos modelos de linguagem de código aberto que, assim como o ChatGPT, são projetados para seguir instruções humanas e responder perguntas dos usuários de forma semelhante a um chatbot. No entanto, a dificuldade está em avaliar efetivamente esses modelos, especialmente para perguntas abertas.
Entra em cena a Chatbot Arena
Aqui, a Chatbot Arena oferece uma abordagem promissora. O sistema Elo para avaliar grandes modelos de linguagem já foi usado pela Anthropic para uma avaliação do Claude.
Na arena, os modelos competem diretamente uns contra os outros e os usuários votam no melhor modelo interagindo com eles. A plataforma coleta todas as interações dos usuários, mas usa apenas os votos lançados com os nomes dos modelos desconhecidos. De acordo com a LMSYS, cerca de 4.700 votos anônimos válidos foram recebidos uma semana após o lançamento, e até o início de maio, esse número havia crescido para cerca de 13.000.
Os resultados até agora mostram uma “lacuna substancial” entre modelos proprietários e de código aberto, de acordo com a LMSYS. No entanto, os modelos de código aberto representados na arena também tinham significativamente menos parâmetros, variando de três a 14 bilhões. Sem contar empates, o GPT-4 vence 82% dos duelos contra o Vicuna-13B e 79% dos duelos contra o GPT-3.5-turbo. O Claude da Anthropic supera o GPT-3.5 na arena e está no mesmo nível do GPT-4.
Além da competição na Arena, o modo Lado a Lado é particularmente conveniente: você pode selecionar modelos de linguagem de código aberto individuais e alimentá-los com o mesmo estímulo ao mesmo tempo. Os resultados podem ser comparados em tempo real.
Acesse a Chatbot Arena se você quiser participar da votação ou encontrar um modelo de linguagem de código aberto útil para você. A plataforma Playground do antigo CEO do GitHub, Nathaniel Friedman, funciona de forma semelhante.
