
A Ponte Visão-Robótica (do inglês Vision-Robotics Bridge – VRB) aprende as possibilidades dos ambientes para acelerar o aprendizado dos robôs.
Vários projetos de pesquisa estão investigando como os robôs podem aprender a partir de vídeos, pois não há dados de treinamento suficientes para os robôs – uma das razões pelas quais a OpenAI, por exemplo, interrompeu sua própria pesquisa em robótica.
Obter dados de treinamento abrangentes para robôs exigiria que muitos robôs realizassem ações no mundo real, mas eles precisariam ser treinados antecipadamente – um problema de causa e efeito. O treinamento por meio de vídeos é visto como uma possível solução, pois modelos de IA poderiam aprender como os humanos interagem com o ambiente a partir dos dados de vídeo e, em seguida, transferir essas habilidades para os robôs.
A Ponte Visão-Robótica desenvolve um modelo de possibilidades para robôs
O termo “possibilidades”, cunhado pelo psicólogo americano James J. Gibson, refere-se ao fato de que os seres vivos não enxergam objetos e características de seu ambiente em termos de suas qualidades, mas sim principalmente como uma oferta ao indivíduo. Por exemplo, os seres vivos não percebem um rio simplesmente como água em movimento, mas como uma oportunidade para beber.
A equipe da Universidade Carnegie Mellon e da Meta AI é guiada por esse conceito e define possibilidade no contexto da robótica como a soma do ponto de contato e das trajetórias pós-contato. O modelo de IA aprende a partir de vídeos para identificar objetos com ações possíveis, assim como padrões de movimento possíveis após agarrar um objeto.
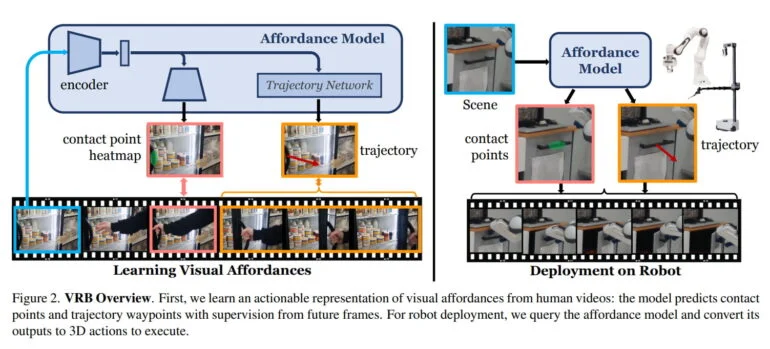
Por exemplo, ele aprende que uma geladeira é aberta puxando a alça e em que direção uma pessoa a puxa. No caso de uma gaveta, ele reconhece a alça e aprende a única direção correta de movimento para abri-la.
VRB se prova em 200 horas de testes no mundo real.
Na robótica, a VRB tem como objetivo fornecer a um robô uma percepção contextualizada para ajudá-lo a aprender suas tarefas mais rapidamente. A equipe demonstra que a VRB é compatível com quatro paradigmas de aprendizado diferentes e aplica a VRB em quatro ambientes do mundo real, em mais de dez tarefas diferentes, utilizando duas plataformas de robô diferentes.
Em experimentos extensivos com duração de mais de 200 horas, a equipe demonstrou que a VRB é muito superior às abordagens anteriores. No futuro, os pesquisadores planejam aplicar seu método em tarefas mais complexas e com várias etapas, incorporar conceitos físicos, como força e informações táteis, e investigar as representações visuais aprendidas pela VRB.
Mais informações estão disponíveis na página do projeto VRB. O código e o conjunto de dados também devem estar disponíveis em breve lá.
