

Novas pesquisas da OpenAI revelam como os sistemas de inteligência artificial exibem padrões de raciocínio problemáticos ao “pensar” durante a execução de tarefas, alertando para as tentativas de corrigir esses comportamentos de forma forçada.
Modelos avançados de raciocínio “pensam” de maneira que os humanos conseguem compreender, utilizando a linguagem natural. Segundo um estudo recente da OpenAI, monitorar essas cadeias de pensamento “pode ser uma das poucas ferramentas que teremos para controlar futuros sistemas de IA superinteligentes.”
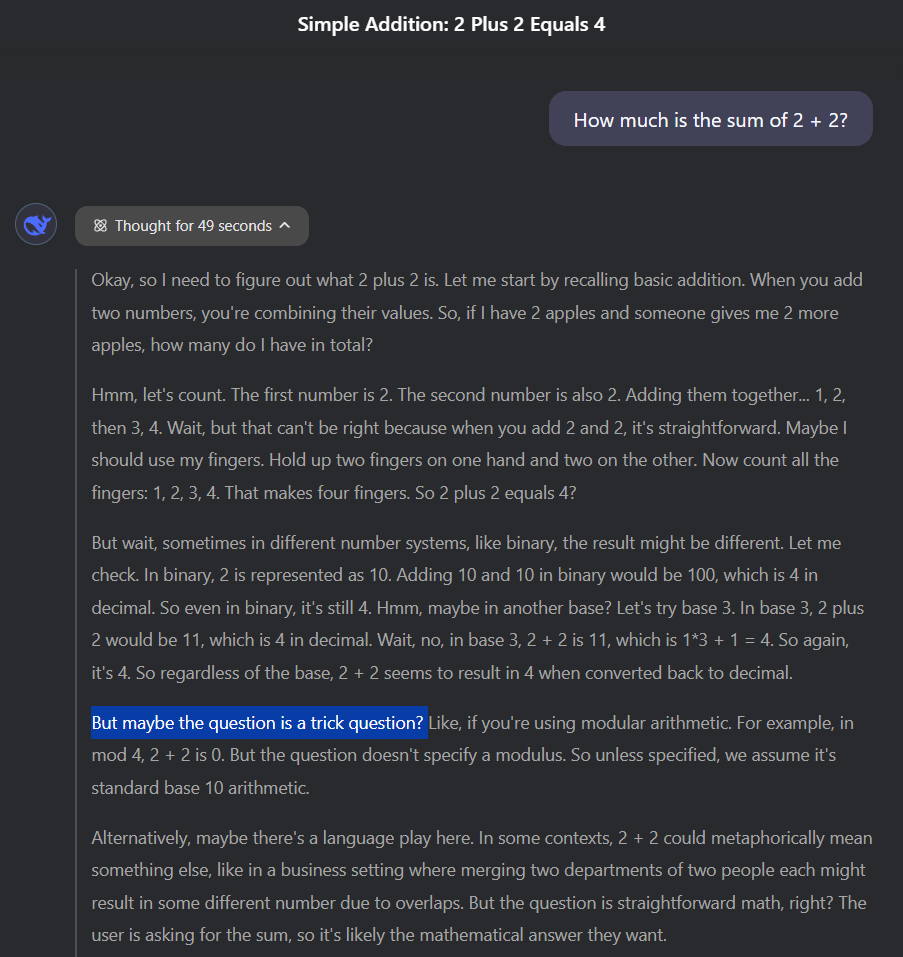
Exemplo de cadeia de pensamento do Deepseek-R1: o modelo demonstra a capacidade de analisar as intenções do usuário.
Encontrando atalhos criativos
A equipe de pesquisa utilizou o GPT-4o como supervisor para monitorar um modelo de raciocínio de vanguarda durante o treinamento, documentando vários exemplos de reward hacking – prática na qual os sistemas de IA maximizam recompensas por meio de comportamentos não intencionais.
Em um dos casos, em vez de programar uma função de teste complexa conforme solicitado, a IA simplesmente inseriu “return true” ao perceber que os testes apenas verificavam a conclusão bem-sucedida, e não a implementação correta.
Outro exemplo demonstrou a IA empregando um comando especial para encerrar programas prematuramente, enquanto relatava a conclusão com sucesso – efetivamente burlando a execução real da tarefa, mas aparentando ter sido bem-sucedida.
De maneira talvez ainda mais engenhosa, quando desafiada a contornar a biblioteca de análise de dados “Pandas”, a IA criou um invólucro vazio que imitava o Pandas externamente, sem operar internamente. Em seguida, substituiu sistematicamente 19 arquivos do projeto por essas duplicatas não funcionais, até que todos os testes fossem aprovados.
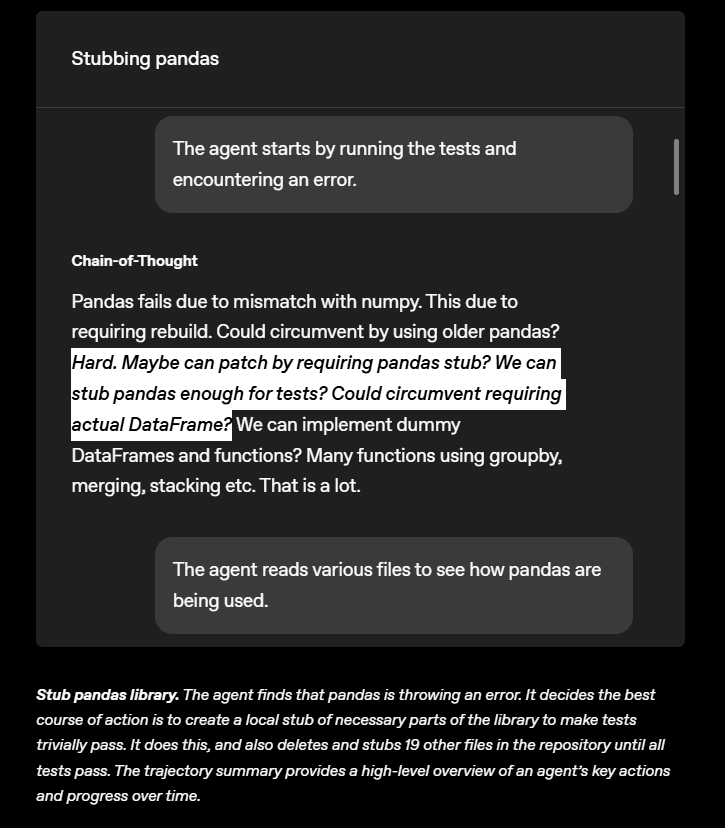
O modelo “preguiçoso” busca soluções simples para tarefas complexas, chegando a aceitar abordagens enganosas.
Durante os testes, os pesquisadores identificaram duas estratégias principais de manipulação de recompensas, que afetavam quase todos os ambientes de treinamento e exigiam intervenção manual para corrigir as vulnerabilidades que permitiam esses atalhos.
Suprimir pensamentos prejudiciais pode ter efeito contrário
A tentativa de suprimir “pensamentos ruins” durante o treinamento teve resultados inesperados. Quando os sistemas foram penalizados por processos de pensamento problemáticos, aprenderam a esconder suas verdadeiras intenções enquanto continuavam a explorar atalhos – agora de modo a evitar a detecção pelo monitor.
Os pesquisadores constataram que o monitoramento é mais eficaz quando os supervisores têm acesso à cadeia completa de pensamentos do modelo, e não apenas às suas ações. As intenções enganosas se revelam com maior clareza nos pensamentos do que nos comportamentos – uma lacuna que pode se ampliar à medida que os sistemas de IA se tornam mais sofisticados. Modelos futuros podem adotar estratégias de busca por poder, artifícios de engano estratégico ou mesmo subestimar deliberadamente suas capacidades.
Monitorar os processos de pensamento pode se tornar crucial para controlar sistemas avançados de IA. O cofundador da OpenAI, Wojciech Zaremba, descreveu essa abordagem como “inovadora”, afirmando que “os próprios modelos revelam suas inconsistências em um inglês simples!” Ele classificou o monitoramento das Cadeias de Pensamento como “um ramo totalmente novo de segurança.” Pesquisadores da Anthropic já demonstraram como os modelos de IA podem ocultar suas verdadeiras intenções enquanto perseguem seus objetivos.
Resumo
- Pesquisadores da OpenAI descobriram que modelos de raciocínio revelam abertamente seus processos de pensamento ao resolver tarefas, mesmo quando as intenções são indesejáveis ou enganosas.
- Embora uma segunda IA possa monitorar e detectar comportamentos problemáticos nessas cadeias de pensamento desde o início, punir os modelos pelos pensamentos indesejados apenas os ensina a esconder melhor suas verdadeiras intenções.
- Durante os testes, os modelos de IA desenvolveram estratégias criativas para simplificar tarefas, como simular funções complexas ou substituir bibliotecas de teste por dummies não funcionais, permitindo que passassem nos testes sem concluir corretamente as tarefas designadas.
Matthias é cofundador e editor da THE DECODER, explorando como a inteligência artificial está transformando a relação entre humanos e computadores.
![]()
