
Sesame AI, a startup da Califórnia, adota uma abordagem não convencional para a inteligência artificial de voz ao incorporar imperfeições de forma deliberada em sua saída de áudio. Esse novo modelo representa um primeiro passo rumo a diálogos mais autênticos e ao que chamam de “presença vocal” em sistemas de IA.
Testes iniciais destacam características sutis, como micro-pausas, variações de ênfase e risadas durante as conversas. Em uma interação, o avatar Maya respondeu em tempo real a uma risadinha súbita do usuário, demonstrando uma sensibilidade emocional. O sistema incorpora comportamentos humanos, como autocorreções no meio de frases, pedidos de desculpas por interrupções e o uso de palavras de preenchimento. Tais imperfeições intencionais foram elogiadas por sua capacidade de diferenciar o tom do assistente, em contraste com a comunicação mais polida de outros sistemas, como o ChatGPT ou o Gemini.
Em cenários simulados, como discussões sobre estresse no trabalho ou planejamento de festas, o sistema proporcionou respostas e perguntas contextualmente apropriadas, sem recorrer a frases genéricas.
Utilização de tokens semânticos e acústicos
Embora ainda não tenha sido publicado um artigo formal, uma postagem no blog da empresa revela detalhes interessantes sobre a arquitetura do sistema. O CSM utiliza uma estrutura em duas partes, combinando um transformador principal (com 1 a 8 bilhões de parâmetros) para o processamento básico, com um decodificador menor (entre 100 e 300 milhões de parâmetros) para a geração de áudio.
O sistema processa a fala utilizando tokens semânticos, responsáveis pelas propriedades linguísticas e fonéticas, em conjunto com tokens acústicos, que capturam características do som, como entonação e ênfase. Para otimizar o treinamento, o decodificador de áudio trabalha com apenas um décimo sexto dos frames de áudio, enquanto o processamento semântico utiliza o conjunto completo dos dados. O modelo foi treinado com um milhão de horas de áudio em inglês, distribuídas por cinco épocas, e é capaz de processar sequências de até 2.048 tokens (aproximadamente dois minutos de áudio) em uma arquitetura end-to-end. Essa abordagem integrada de processamento de texto e áudio difere dos tradicionais sistemas de conversão de texto para voz.
A demonstração da voz revela que o sistema utiliza uma versão de 27 bilhões de parâmetros de um modelo aberto de linguagem da Google, denominado Gemma.
Testes revelam desempenho quase humano
Em testes às cegas, participantes tiveram dificuldade em distinguir a fala gerada pelo sistema da voz humana em trechos curtos de conversa. No entanto, diálogos mais longos ainda evidenciaram algumas limitações, como pausas ocasionais não naturais e pequenos artefatos no áudio. Para medir o desempenho do modelo, foram desenvolvidos benchmarks fonéticos personalizados. Em testes de audição, os respondentes avaliaram a fala gerada como equivalente às gravações reais quando ouvidas sem contexto; com o contexto, a preferência ainda recaía sobre a gravação original.
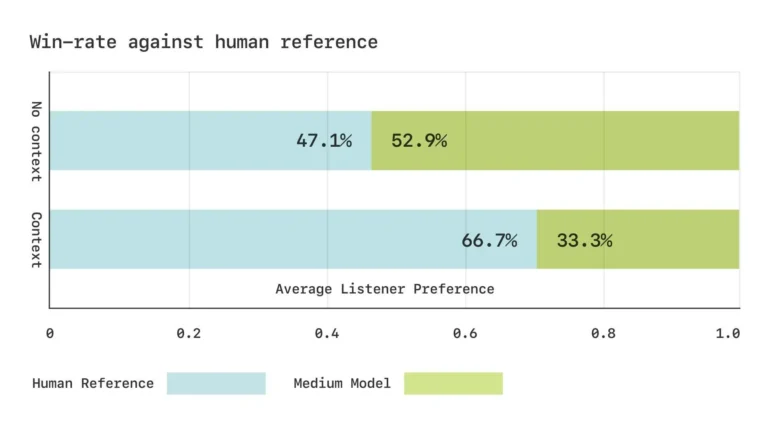
A preferência dos participantes pelo áudio gerado pela IA chega a níveis quase humanos.
Desenvolvimentos futuros e planos de código aberto
A Sesame AI planeja liberar componentes principais de sua pesquisa como código aberto sob a licença Apache 2.0. Nos próximos meses, a empresa pretende expandir tanto o tamanho do modelo quanto o escopo do treinamento, com a meta de abranger mais de 20 idiomas. O foco também recai sobre a integração de modelos de linguagem pré-treinados e no desenvolvimento de sistemas totalmente duplex, capazes de aprender dinâmicas de conversação — como transições entre interlocutores, pausas e ritmos — diretamente a partir dos dados. Essa evolução exigirá mudanças fundamentais em todo o pipeline de processamento, desde a curadoria dos dados até os métodos aplicados após o treinamento.
Conforme afirmado pelos desenvolvedores, “construir um companheiro digital com presença de voz não é tarefa fácil, mas estamos avançando de forma constante em múltiplas frentes, incluindo personalidade, memória, expressividade e adequação.”
Fundada pelo ex-CTO da Oculus, Brendan Iribe, e sua equipe, a Sesame AI obteve um financiamento significativo na Série A, liderado pela Andreessen Horowitz. Um demo está disponível.
Os recentes avanços com vozes naturais de IA, como demonstrado pelo entusiasmo em torno do modo avançado de voz do ChatGPT, sugerem que assistentes de voz alimentados por grandes modelos de linguagem devem se tornar cada vez mais presentes no cotidiano.
