
Pix2pix-zero é projetado para permitir a edição de imagem simples usando Stable Diffusion, mantendo a estrutura da imagem de origem.
Para modelos de gerar imagens com IA, como Stable Diffusion, DALL-E 2 ou Imagen, existem vários métodos, como Inpainting, Prompt-to-Prompt ou InstructPix2Pix, que permitem a manipulação de imagens reais ou geradas.
Pesquisadores da Carnegie Mellon University e da Adobe Research agora apresentam o pix2pix-zero, um método que se concentra em preservar a estrutura da imagem de origem. O método permite que as tarefas de tradução de imagens sejam executadas sem ajuste fino extensivo ou engenharia de prompt.

Pix2pix-zero usa orientação de atenção cruzada
Métodos como Prompt-to-Prompt ou InstructPix2Pix podem alterar a estrutura da imagem original ou cumpri-la tanto que as alterações desejadas não são feitas.
Uma solução é combinar Inpainting e InstructPix2Pix, o que permite mudanças mais direcionadas.
O Pix2pix-zero adota uma abordagem diferente: os pesquisadores sintetizam uma imagem completamente nova, mas usam mapas de atenção cruzada para orientar o processo generativo.
O método suporta mudanças simples, como “gato para cão”, “cão para cão com óculos de sol” ou “esboço para pintura a óleo”.
A entrada é uma imagem original, da qual um modelo BLIP deriva uma descrição de texto, que é então convertida em uma incorporação de texto por CLIPE.
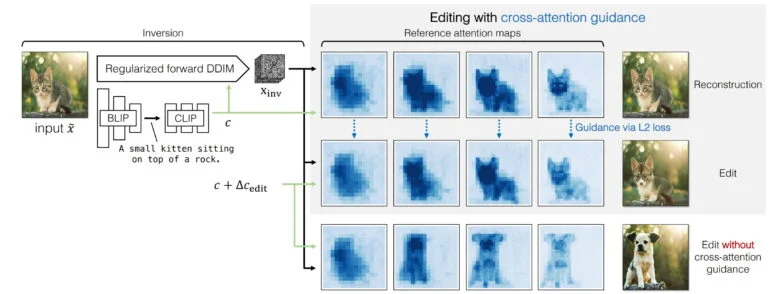
Juntamente com um mapa de ruído invertido, a incorporação de texto é usada para reconstruir a imagem original.
Na segunda etapa, os mapas de atenção cruzada dessa reconstrução, juntamente com a incorporação do texto original e uma nova incorporação do texto para orientar a mudança, são usados para orientar a síntese da imagem desejada.
Como a alteração “gato para cão” não é descrita em detalhes pela entrada de texto, essa nova incorporação de texto não pode ser obtida de um prompt.
Em vez disso, o pix2pix-zero usa GPT-3 para gerar uma série de avisos para “gato”, por exemplo, “Um gato se lava, um gato está observando pássaros em uma janela, …” e para “cão”, por exemplo, “Este é o meu cão, um cão está ofegante depois de uma caminhada, …”.
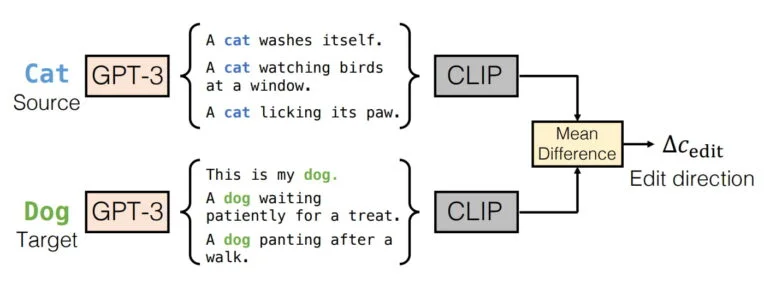
Para esses prompts gerados, o pix2pix-zero calcula primeiro as incorporações de CLIPE individuais e, em seguida, a diferença média de todas as incorporações. O resultado é então usado como uma nova incorporação de texto para a síntese da nova imagem, por exemplo, a imagem de um cão.
Pix2pix-zero fica perto do original
Os pesquisadores usam vários exemplos para mostrar o quão perto o pix2pix-zero permanece da imagem original – embora pequenas mudanças sejam sempre visíveis. O método funciona com imagens diferentes, incluindo fotos ou desenhos, e pode alterar estilos, objetos ou estações.
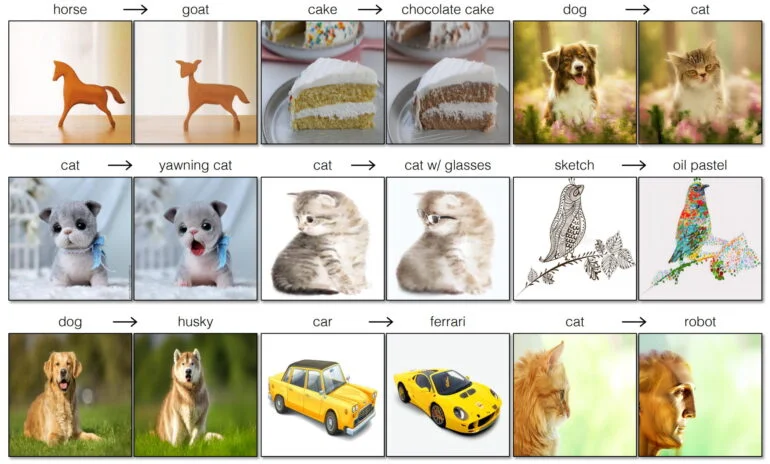
Em comparação com alguns outros métodos, o pix2pix-zero está claramente à frente em termos de qualidade. Uma comparação direta com InstructPix2Pix não é mostrada no artigo.

A qualidade dos resultados também depende da própria difusão estável, de acordo com o artigo.
Os mapas de atenção cruzada usados para orientação mostram em quais recursos da imagem o modelo se concentra em cada etapa de denúncia, mas estão disponíveis apenas em uma resolução de 64 por 64 pixels.
Resoluções mais altas podem fornecer resultados ainda mais detalhados no futuro, de acordo com os pesquisadores.
Outra desvantagem do método baseado em difusão é que ele requer muitas etapas e, portanto, muito poder e tempo de computação. Como alternativa, a equipe propõe um GAN treinado nos pares de imagens gerados pelo pix2pix-zero para a mesma tarefa.
Pares de imagens comparáveis até agora têm sido muito difíceis e caros de gerar, diz a equipe. Uma versão destilada do GAN alcança resultados semelhantes ao pix2pix-zero com uma aceleração de 3.800 vezes. Em uma Nvidia A100, isso equivale a 0,018 segundos por quadro.
A variante GAN permite, assim, que as alterações sejam feitas em tempo real.
Mais informações e exemplos podem ser encontrados na página do projeto pix2pix-zero.
