
Um prompt complexo da empresa de marketing em nuvem Salesforce visa melhorar a qualidade dos resumos de artigos usando o GPT-4.
O prompt Cadeia de Densidade pede primeiro ao GPT-4 para criar um primeiro rascunho de um resumo com o menor número possível de elementos. Nas próximas etapas, o prompt pede ao GPT-4 para revisar esse resumo e adicionar mais detalhes.
Assim como no prompt de cadeia de pensamento, o modelo usa a primeira saída gerada como um modelo para a próxima geração. Quanto mais vezes o modelo passar por esse processo, maior será a densidade de informações no resumo para o mesmo comprimento de caractere.
“Os resumos gerados pelo CoD são mais abstratos, exibem mais fusão e têm menos viés de chumbo do que os resumos GPT-4 gerados por um prompt de baunilha”, escreve a equipe.
Article: {{article}
You will generate increasingly concise entity-dense summaries of the above article. Repeat the following 2 steps 5 times.
Step 1: Identify 1-3 informative entities (delimited) from the article which are missing from the previously generated summary.
Step 2: Write a new denser summary of identical length which covers every entity and detail from the previous summary plus the missing entities.
A missing entity is
- Relevant: to the main stories.
- Specific: descriptive yet concise (5 words or fewer).
- Novel: not in the previous summary.
- Faithful: present in the article.
- Anywhere: located in the article.
Guidelines:
- The first summary should be long (4-5 sentences, ~80 words), yet highly non-specific, containing little information beyond the entities marked as missing. Use overly verbose language and fillers (e.g., "this article discusses") to reach ~80 words.
- Make every word count. Rewrite the previous summary to improve flow and make space for additional entities.
- Make space with fusion, compression, and removal of uninformative phrases like "the article discusses".
- The summaries should become highly dense and concise, yet self-contained, e.g., easily understood without the article.
- Missing entities can appear anywhere in the new summary.
- Never drop entities from the previous summary. If space cannot be made, add fewer new entities.
Remember: Use the exact same number of words for each summary.
Answer in JSON. The JSON should be a list (length 5) of dictionaries whose keys are "missing_entities" and "denser_summary".
Bild: Salesforce
A complexidade dos resumos
A equipe de pesquisa testou o prompt em 100 artigos de notícias da CNN e do DailyMail. Os revisores humanos, neste caso quatro dos autores do artigo, classificaram os resumos com a melhor classificação após cerca de três passagens.
Em média, o GPT-4 classificou os resumos mais bem nas dimensões de informação, qualidade, coerência, atribuição e “geral” após duas passagens. Diz-se que o método CoD é superior a um prompt mais simples testado (“Escreva um resumo MUITO curto do artigo. Não exceda 70 palavras.”).
“Descobrimos que um grau de densificação é preferível, no entanto, quando os resumos contêm muitas entidades por token, é muito difícil manter a legibilidade e a coerência”, escreve a equipe.
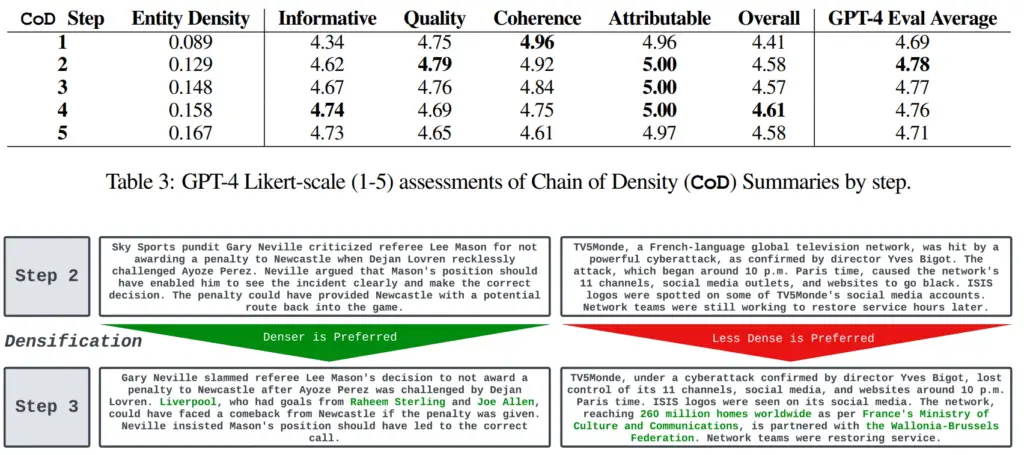
Bild: Salesforce
Em geral, o primeiro e o último passos pontuam o pior, com os três resumos do meio próximos. Que a primeira pontuação do resumo seja menor faz sentido, considerando que o prompt pede ao modelo para escrever um resumo superficial primeiro.
O fato de os resultados serem tão próximos também mostra como é difícil avaliar textos acima de um determinado nível. Isso, por sua vez, dificulta a mensuração do impacto da engenharia imediata.
A equipe de pesquisa publica um conjunto de dados de 500 resumos de CoD anotados e 5000 não anotados ao lado do prompt.
