
OLMo 2 32B estabelece um novo padrão para LLMs verdadeiramente open-source
Um novo modelo de linguagem open-source alcançou um desempenho comparável aos principais sistemas comerciais, mantendo total transparência.
O Allen Institute for Artificial Intelligence (Ai2) anunciou que seu modelo OLMo 2 32B supera tanto o GPT-3.5-Turbo quanto o GPT-4o mini, disponibilizando publicamente seu código, os dados de treinamento e os detalhes técnicos.
O modelo se destaca pela eficiência, consumindo apenas um terço dos recursos computacionais necessários por modelos similares, como o Qwen2.5-32B, o que o torna particularmente acessível para pesquisadores e desenvolvedores com recursos limitados.
Construindo um sistema de IA transparente
A equipe de desenvolvimento utilizou uma abordagem de treinamento em três fases. Inicialmente, o modelo aprendeu padrões básicos de linguagem a partir de 3,9 trilhões de tokens; em seguida, aprofundou seus estudos em documentos de alta qualidade e conteúdos acadêmicos; e, por fim, aprimorou a capacidade de seguir instruções utilizando a estrutura Tulu 3.1, que combina técnicas supervisionadas e de aprendizado por reforço.
Para gerenciar o processo, a equipe criou o OLMo-core, uma nova plataforma de software que coordena eficientemente múltiplos computadores, preservando o progresso do treinamento. O treinamento propriamente dito ocorreu na Augusta AI, uma rede de supercomputadores composta por 160 máquinas equipadas com GPUs H100, atingindo velocidades de processamento superiores a 1.800 tokens por segundo por GPU.
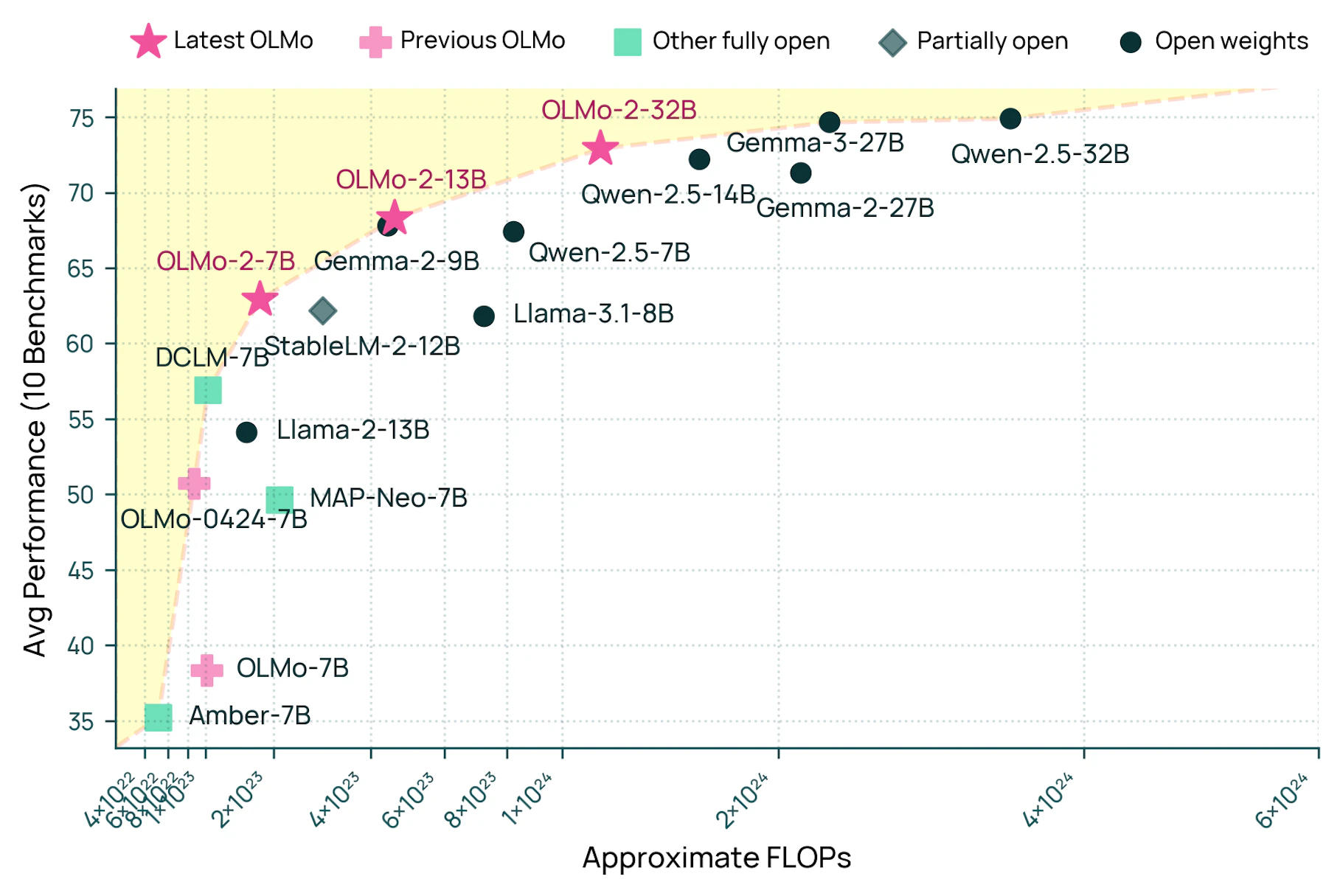
Embora o Qwen2.5 e o Gemma 3 apresentem um desempenho médio melhor em benchmarks do que o OLMo 2 32B, tanto a Alibaba quanto o Google divulgaram apenas os pesos dos modelos, sem oferecer implementações open-source completas.
Enquanto muitos projetos de IA, como o Llama da Meta, afirmam ser open-source, o OLMo 2 cumpre todos os três critérios essenciais: código do modelo, pesos e dados de treinamento públicos. A equipe disponibilizou tudo, inclusive o conjunto de dados de treinamento Dolmino, possibilitando total reprodutibilidade e análise.
“Com apenas um pouco mais de progresso, qualquer um poderá realizar o pré-treinamento, treinamento intermediário ou pós-treinamento, conforme necessário para obter um modelo da classe do GPT-4. Isso representa uma mudança significativa em como a IA open-source pode evoluir para aplicações reais”, declara Nathan Lambert, do Ai2.
Esse avanço se baseia no trabalho anterior com o Dolma, em 2023, que ajudou a estabelecer uma base para o treinamento de IA open-source. A equipe também publicou diversos checkpoints – versões do modelo de linguagem em diferentes momentos do treinamento. Um artigo divulgado em dezembro, juntamente com as versões 7B e 13B do OLMo 2, fornece mais embasamento técnico.
A diferença entre sistemas de IA open-source e privados reduziu para aproximadamente 18 meses, de acordo com a análise de Lambert. Embora o OLMo 2 32B corresponda, em termos de treinamento básico, ao Gemma 3 27B do Google, o Gemma 3 apresenta um desempenho superior após o ajuste fino, sugerindo que há espaço para melhorias nos métodos de pós-treinamento open-source.
A equipe planeja aprimorar o raciocínio lógico do modelo e expandir sua capacidade de lidar com textos mais extensos. Usuários podem testar o OLMo 2 32B por meio do Chatbot Playground do Ai2.
Enquanto o Ai2 também divulgou, em janeiro, o modelo maior Tülu-3-405B, que supera o GPT-3.5 e o GPT-4o mini, Lambert explica que este não é totalmente open-source, já que o laboratório não participou do seu pré-treinamento.
