
A MosaicML lançou o melhor modelo de linguagem de fonte aberta até agora, licenciado para uso comercial. Uma das variantes pode até lidar com livros inteiros.
O MPT-7B da MosaicML é um grande modelo de linguagem com quase 7 bilhões de parâmetros, que a equipe treinou em seu próprio conjunto de dados de quase um trilhão de tokens.
A MosaicML seguiu o regime de treinamento do modelo LLaMA da Meta. O treinamento custou quase US$ 200.000 e levou 9,5 dias usando a plataforma MosaicML.
MosaicML MPT-7B é o melhor modelo de código aberto até agora.
Segundo a MosaicML, o MPT-7B corresponde ao desempenho do modelo LLaMA de 7 bilhões de parâmetros da Meta, tornando-se o primeiro modelo de fonte aberta a atingir esse nível, à frente do OpenLLaMA.
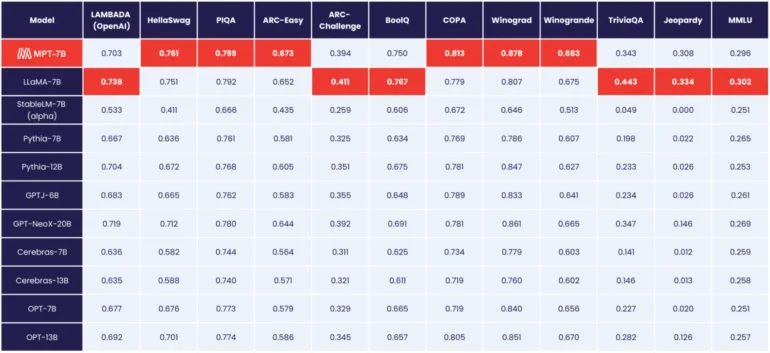
Ao contrário dos modelos da Meta, no entanto, o MPT-7B é licenciado para uso comercial.
Além do modelo “MPT-7B Base”, a MosaicML também lança três variantes: MPT-7B-StoryWriter-65k+, MPT-7B-Instruct e MPT-7B-Chat.
A MosaicML lança modelo de linguagem com contexto de 65.000 tokens
MPT-7B-Instruct é um modelo para seguir instruções, e o modelo Chat é uma variante de chatbot no estilo Alpaca ou Vicuna.
Com o MPT-7B-StoryWriter-65k+, a MosaicML também lança um modelo capaz de ler e escrever histórias com comprimentos de contexto muito longos. Para esse propósito, o MPT-7B foi ajustado com um comprimento de contexto de 65.000 tokens usando um subconjunto do conjunto de dados books3. A maior variante GPT-4 da OpenAI pode lidar com 32.000 tokens.
Segundo a MosaicML, o modelo pode escalar além de 65.000 tokens com algumas otimizações, e a equipe demonstrou até 84.000 tokens em um único nó usando GPUs Nvidia A100-80GB. Mas mesmo com 65.000 tokens, era possível ler romances inteiros e escrever um epílogo.

Todos os modelos MPT-7B estão disponíveis no GitHub.
