
De certa forma, humanos e grandes modelos de linguagem parecem exibir comportamentos semelhantes: eles respondem particularmente bem a informações no início ou no final de um conteúdo. Informações no meio tendem a se perder.
Pesquisadores da Universidade de Stanford, da Universidade da Califórnia, Berkeley, e da Samaya AI descobriram um efeito em LLMs (Large Language Models) que lembra o efeito de primazia/recência conhecido em humanos. Isso significa que as pessoas tendem a lembrar do conteúdo no início e no final de uma declaração. O conteúdo no meio é mais propenso a ser ignorado.
De acordo com o estudo, um efeito similar ocorre com grandes modelos de linguagem: quando solicitados a recuperar informações de uma entrada, os modelos têm melhor desempenho quando as informações estão no início ou no final da entrada.
No entanto, quando a informação relevante está no meio da entrada, o desempenho cai significativamente. Esse declínio no desempenho é particularmente pronunciado quando o modelo é solicitado a responder a uma pergunta que requer extrair informações de múltiplos documentos – o equivalente a um estudante tendo que identificar informações relevantes de vários livros para responder a uma pergunta em um exame.
Quanto maior a quantidade de entrada que o modelo precisa processar simultaneamente, pior tende a ser o seu desempenho. Isso pode ser um problema em cenários do mundo real onde é importante processar grandes quantidades de informações de forma simultânea e equitativa.
O resultado também sugere que há um limite para o quão efetivamente grandes modelos de linguagem podem utilizar informações adicionais, e que “mega-prompts” com instruções particularmente detalhadas provavelmente farão mais mal do que bem.
Quão úteis são os LLMs com grandes janelas de contexto?
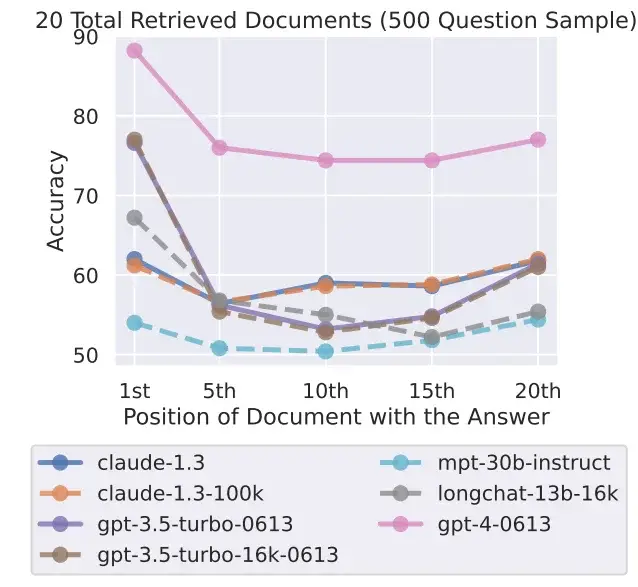
O fenômeno de “perda no meio” também ocorre com modelos especificamente projetados para lidar com muitos contextos, como o GPT-4 32K ou o Claude com sua janela de contexto de 100.000 tokens.
Os pesquisadores testaram sete modelos de linguagem abertos e fechados, incluindo o novo GPT-3.5 16K e o Claude 1.3 com 100K. Todos os modelos apresentaram uma curva em forma de U mais ou menos pronunciada, dependendo do teste, com melhor desempenho em tarefas em que a solução está no início ou no final do texto.

Isso levanta a questão da utilidade de modelos com uma grande janela de contexto quando resultados melhores podem ser obtidos ao processar o contexto em pedaços menores. O atual modelo líder, o GPT-4, também mostra esse efeito, mas em um nível de desempenho geral mais alto.
A equipe de pesquisa reconhece que ainda não se entende completamente como os modelos processam a linguagem. Essa compreensão precisa ser aprimorada por meio de novos métodos de avaliação, e também podem ser necessárias novas arquiteturas.
Há também a necessidade de estudar como o design dos prompts afeta o desempenho do modelo, afirmam os pesquisadores. Tornar os sistemas de IA mais cientes da tarefa em questão em um prompt poderia melhorar sua capacidade de extrair informações relevantes.
