
Sistemas como ChatGPT ou Midjourney são principalmente especialistas em texto ou imagem. O que acontece quando você combina essas habilidades? Pesquisadores da Microsoft estão testando isso com o Kosmos-1, um modelo que combina imagem e texto.
Modelos multimodais de IA poderiam desenvolver uma melhor compreensão do mundo aprendendo com diferentes fontes de dados, acreditam alguns pesquisadores. Eles podem combinar conhecimentos de diferentes modalidades para resolver tarefas como descrever imagens em linguagem natural.
“Sendo uma parte básica da inteligência, a percepção multimodal é uma necessidade para alcançar a inteligência artificial geral, em termos de aquisição de conhecimento e aterramento no mundo real”, escreve a equipe de pesquisa da Microsoft. Ele apresenta o Kosmos-1, um modelo multimodal de linguagem grande (MLLM).
Além da linguagem e da percepção multimodal, uma possível inteligência geral artificial (agi) também precisaria da capacidade de modelar o mundo e agir, dizem eles.
Kosmos-1 entende línguas e imagens
A Microsoft treinou o Kosmos-1 com dados de imagem e idioma parcialmente relacionados, como pares de palavras e imagens. Além disso, a equipe usou grandes quantidades de texto na Internet, como é comum com grandes modelos de linguagem.
Como resultado, o modelo pode entender imagens e texto, incluindo descrever imagens em linguagem natural, reconhecer texto em imagens, escrever legendas para imagens e responder a perguntas sobre imagens. O Kosmos-1 pode executar essas tarefas mediante solicitação direta ou, semelhante ao ChatGPT, em uma situação de diálogo.

Por ter as mesmas capacidades de texto que os grandes modelos de linguagem, também pode usar métodos como a cadeia de pensamento para produzir melhores resultados.

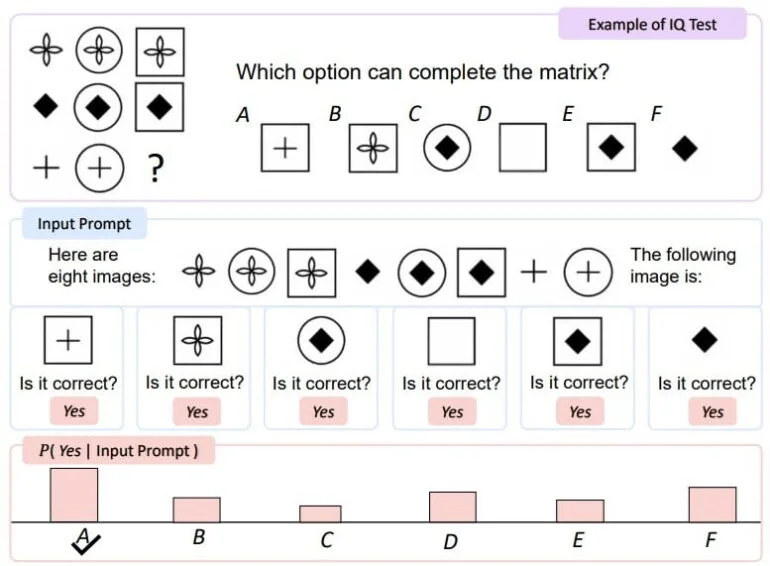
Em um teste de QI visual, o KOSMOS-1 teve um desempenho cerca de cinco a nove por cento melhor do que o acaso, o que a equipe de pesquisa acredita que mostra que o KOSMOS-1 pode perceber padrões conceituais abstratos em um contexto não-verbal, combinando raciocínio não-verbal com a percepção de padrões linguísticos. No entanto, ainda há uma grande lacuna de desempenho com o nível médio de adultos.
A capacidade dos modelos multimodais de representar conexões implícitas entre diferentes conceitos já foi demonstrada no estudo OpenAI de neurônios CLIP.
O Desenvolvimento de IAs multimodelos é o próximo passo
A abordagem da Microsoft não é nova; a empresa alemã Aleph Alpha apresentou o MAGMA, um modelo combinado de linguagem de imagem, e o M-Vader, um método para solicitação multimodal. O Google apresentou o “Futuro da Pesquisa do Google” na primavera de 2021 com o MUM, que permite consultas multimodais e fornece mais conhecimento contextual.
O Flamingo da Deepmind, que também combina linguagem e processamento de imagens, vai em uma direção semelhante. A equipe de pesquisa da Microsoft também usou o Flamingo para comparar o desempenho do Kosmos-1 em testes como legendas de imagens e responder a perguntas sobre o conteúdo da imagem. O modelo da Microsoft teve um desempenho tão bom e, em alguns casos, um pouco melhor do que o Kosmos-1.
Os pesquisadores também treinaram um modelo de linguagem (LLM) nos mesmos dados de texto que o Kosmos-1 e fizeram com que os dois modelos competissem em tarefas apenas de linguagem.
Aqui, os dois modelos empataram na maioria dos casos, com o Kosmos-1 tendo um desempenho significativamente melhor em tarefas de raciocínio visual que exigem uma compreensão das propriedades dos objetos do mundo real cotidiano, como cor, tamanho e forma, diz a equipe.
A razão para o desempenho superior do KOSMOS-1 é que ele tem transferibilidade de modalidade, o que permite que o modelo transfira conhecimento visual para tarefas de linguagem. Pelo contrário, o LLM tem que confiar em conhecimento textual e pistas para responder a perguntas visuais de senso comum, o que limita sua capacidade de raciocinar sobre as propriedades do objeto.
Do Paper
Modelos de linguagem grandes multimodais combinam o melhor dos dois mundos, escrevem os pesquisadores: Aprendizagem em contexto e a capacidade de seguir instruções de linguagem natural de grandes modelos de linguagem, e “a percepção está alinhada com modelos de linguagem treinando em corpora multimodais”.
Os resultados do Kosmos-1 são “promissores” em uma ampla gama de tarefas de linguagem e multimodais, dizem eles. Modelos multimodais ofereceriam novas capacidades e oportunidades em comparação com grandes modelos de linguagem.
O Kosmos-1 tem 1,6 bilhão de parâmetros, o que é minúsculo em comparação com os grandes modelos de linguagem atuais. A equipe gostaria de ampliar o Kosmos-1 para incluir mais modalidades, como a fala, no treinamento de modelos. Um modelo maior com mais modalidades poderia então superar muitas das limitações atuais, escrevem os pesquisadores.
Artigo baseado no the-decoder
