
ヴィジョン・ロボティクス・ブリッジ(VRB)は、ロボットの学習を加速させるために環境のアフォーダンスを学習する。
いくつかの研究プロジェクトでは、ロボットが動画からどのように学習できるかを研究している。ロボットのトレーニングデータが十分でないことが、例えばオープンAIが独自のロボット研究を中止した理由のひとつだ。
ロボットのための包括的な訓練データを得るには、多くのロボットが現実世界で行動を行う必要があるが、事前に訓練する必要がある。AIモデルは、ビデオデータから人間が環境とどのように相互作用するかを学習し、そのスキルをロボットに伝達することができる。
ビジョン-ロボティクス・ブリッジは、ロボットのためのアフォーダンス・モデルを開発する。
アフォーダンス」とは、アメリカの心理学者ジェームズ・J・ギブソンによって作られた造語で、生物は環境の物体や特徴をその性質として見るのではなく、主に個体への提供物として見るという事実を指す。例えば、生物は川を単に動いている水としてではなく、水を飲む機会として認識する。
カーネギーメロン大学とメタAIのチームは、このコンセプトに導かれ、ロボット工学の文脈における可能性を、接触点と接触後の軌道の合計として定義している。このAIモデルは動画から学習し、可能なアクションを持つ物体と、物体を把持した後に可能な動作パターンを特定する。
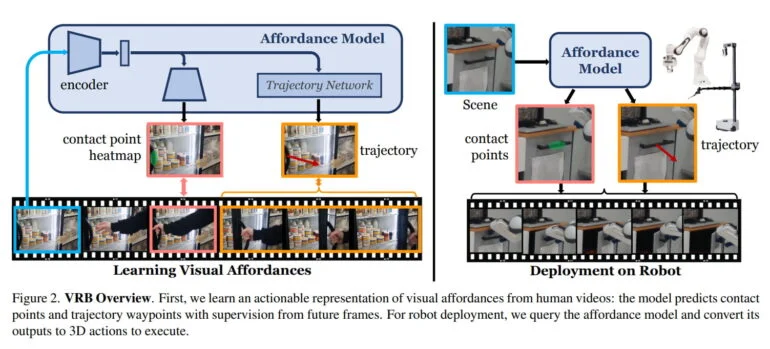
例えば、冷蔵庫は取っ手を引くと開くこと、そして人がどの方向に引くかを学習する。引き出しの場合は、取っ手を認識し、それを開けるための唯一の正しい動作方向を学習する。
VRBは、200時間に及ぶ実環境テストでその実力を証明している。
ロボット工学においてVRBは、ロボットがより速くタスクを学習できるよう、文脈に応じた知覚を提供することを目的としている。研究チームは、VRBが4つの異なる学習パラダイムに適合することを実証し、2つの異なるロボットプラットフォームを使用して、4つの実環境、10以上の異なるタスクにVRBを適用した。
200時間を超える大規模な実験において、研究チームはVRBがこれまでのアプローチよりもはるかに優れていることを実証した。研究チームは今後、この手法をより複雑で多段階のタスクに適用し、力や触覚情報などの物理的概念を取り入れ、VRBによって学習される視覚表現について調査する予定である。
詳細については、VRBプロジェクトのページを参照されたい。コードとデータセットも近日中に公開される予定だ。
