
OpenAIは、いくつかの数学的問題を解くための最先端の(SOTA)AIモデルを紹介している。その基礎となるプロセスは、より優れた言語モデル一般につながる可能性がある。
Let's Verify Step by Step」と題された論文の中で、OpenAIチームは、MATHデータセットの問題を解くために、GPT-4ベースのモデルをいくつか訓練した。その目的は、報酬モデルを訓練するための2種類のフィードバックプロセスを比較することだった。
具体的には、AIモデルがタスクの最終的な結果についてフィードバックを受ける「結果監視」と、モデルが推論の特定のステップごとにフィードバックを受ける「プロセス監視」を比較した。実際には、後者のプロセスは人間のフィードバックを必要とするため、大規模なモデルや多様なタスクにはコストがかかる。したがって、今回の研究は、OpenAIの将来の方向性を決定する可能性のある調査である。
プロセス監視:アライメント税を回避する方法
数学的なタスクにおいて、OpenAIはプロセス監視が大規模モデルでも小規模モデルでも有意に良い結果をもたらすことを実証した。幻覚や論理的エラーは、今日の最高のモデルでさえよくあることだが、それを減らすことができる。
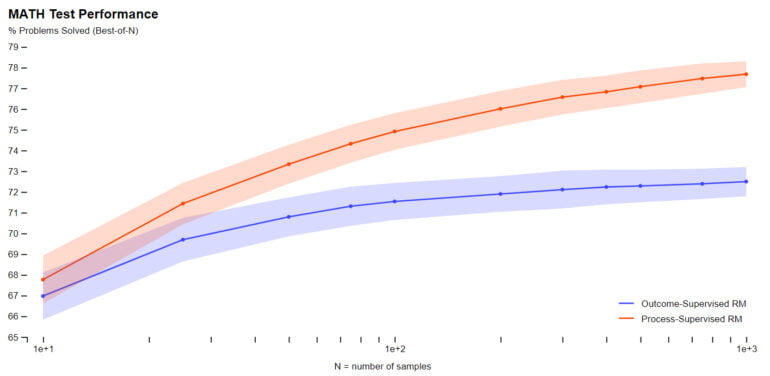
さらにOpenAIによれば、正しい中間ステップに報酬を与えることで、人間の価値観や期待に忠実であるためにモデルのパフォーマンスが低下する「アライメント税」として知られる現象を回避できる。テストされた数学のタスクの場合、同社はアライメント税が減少することさえ発見した。
「これらの結果が、数学の領域を超えてどの程度広く一般化するかは未知数であり、今後の研究では、他の領域におけるプロセス監督の影響を調査することが重要であると考えています。もしこれらの結果が一般化すれば、プロセス監督は、結果監督よりも効率的でアライメントが取れている方法という、両方の長所を提供してくれることがわかるかもしれません。”
オープンAI
OpenAIは人間がラベル付けしたデータセットを利用可能にした
数学以外の領域におけるプロセス監督の適用可能性をさらに調査する必要がある。このプロセスを支援するために、OpenAIは独自のモデルで使用されているPRM800Kデータセットを公開しました。
OpenAIの共著者であり共同設立者であるJohn Schulmanは、最近、大規模な言語モデルにおいて望ましい行動を形成する際の報酬モデルの中心的な役割について詳しく講演を行った。
