
MosaicMLは、商用利用が許可されている最高のオープンソース言語モデルを発表しました。そのバリエーションの1つは、完全な書籍の処理すら可能です。
MosaicMLのMPT-7Bは、約7,000億のパラメータを持つ大規模な言語モデルで、チームが1兆トークンにも及ぶ独自のデータセットでトレーニングしました。
MosaicMLはMetaのLLaMAモデルのトレーニングスキームに従いました。トレーニングには約20万ドルかかり、MosaicMLプラットフォームを使用して9.5日間かかりました。
MosaicML MPT-7Bは、現時点で最高のオープンソースモデルです。
MosaicMLによれば、MPT-7BはMetaの7,000億パラメータのLLaMAモデルと同等の性能を持っており、OpenLLaMAを先行し、このレベルに到達した最初のオープンソースモデルとなっています。
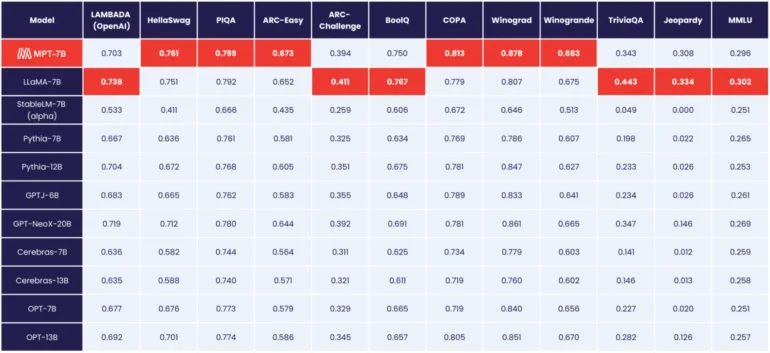
Metaのモデルとは異なり、MPT-7Bは商用利用が許可されています。
「MPT-7B Base」というモデルのほかに、MosaicMLは「MPT-7B-StoryWriter-65k+」、「MPT-7B-Instruct」、「MPT-7B-Chat」という3つの変種もリリースします。
MosaicMLは、65,000トークンのコンテキストを持つ言語モデルをリリースします。
「MPT-7B-Instruct」は、指示に従うためのモデルであり、「Chat」モデルはAlpacaやVicunaスタイルのチャットボットのバリエーションです。
「MPT-7B-StoryWriter-65k+」では、非常に長いコンテキストのストーリーの読み書きができるモデルも提供されます。このために、MPT-7Bは「books3」データセットのサブセットを使用して65,000トークンのコンテキスト長に調整されました。OpenAIのGPT-4の最大バリエーションは32,000トークンを扱うことができます。
MosaicMLによれば、このモデルはいくつかの最適化を施すことで65,000トークンを超えることができ、Nvidia A100-80GB GPUを1つのノードで使用して84,000トークンまでデモンストレーションされました。しかし、65,000トークンでも小説全体を読んでエピローグを書くことができたとのことです。

すべてのMPT-7BモデルはGitHubで利用可能です。
