
StyleDropはあらゆる画像のスタイルを学習し、生成AIモデルがそれを再現するのを助ける。Googleの手法は、Dreambooth、LoRA、Textual Inversionといった他の手法を凌駕している。
グーグルの新しい手法は、ミューズのテキスト画像モデルを使用して、画像を特定のスタイルに合成することができる。StyleDropは、配色、シェーディング、デザインパターン、ローカルおよびグローバルエフェクトなど、カスタムスタイルの複雑さをキャプチャします。Googleによると、入力として必要なのは1枚の画像だけです。
StyleDropは、少数の学習可能なネットワークパラメータを調整することで新しいスタイルを学習し、人間または自動フィードバックによる反復学習によってモデルの品質を向上させる。
StyleDropは少ないサンプル数で高速に学習します。
具体的には、StyleDropは入力画像に対して学習を行い、その画像を再現するための画像セットを生成します。これらの画像から、CLIPスコアまたは人間によるフィードバックにより、最高品質のものが選択され、さらなる学習に使用されます。画像が高品質とみなされるのは、元の画像の内容ではなくスタイルを再現している場合である。
人間のフィードバックがあったとしても、全プロセスにかかる時間は3分未満である、と研究チームは述べている。これは、StyleDropが反復学習に必要とする画像が12枚以下だからだという。
StyleDropは、Dreambooth、LoRAs、Textual Inversion in Image、Stable Diffusionなど、テキストから画像モデルへスタイルを転送する他の手法を凌駕しているという。

スタイルはStyleDrop、オブジェクトはDreambooth
“StyleDropは、幅広いスタイルにおいて、テクスチャ、シェーディング、構造のニュアンスを、これまでのアプローチよりも格段によく捉えることができ、従来よりもはるかに高度なスタイリングの制御が可能であることが確認された “と、研究チームは述べている。
また、StyleDropをDreamboothと組み合わせることで、異なるスタイルの新しいオブジェクトを画像として学習・作成することができ、Museでこのメソッドを使用することで、カスタムスタイルのカスタムオブジェクトを作成することができます。
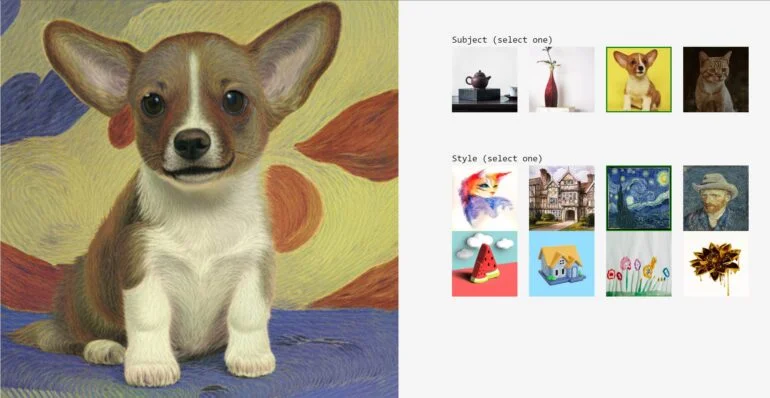
GoogleはStyleDropを多用途なツールとみなしており、その使用例のひとつは、デザイナーや企業がブランド資産を使ってトレーニングし、そのスタイルで新しいアイデアを素早くプロトタイプ化できるようにすることだ。より詳しい情報はStyleDropのプロジェクトページに掲載されている。
