
AudioPaLMによって、グーグルは大規模なPaLM-2言語モデルに音声機能を追加する。これにより、元の話者の声を使った音声翻訳が可能になる。
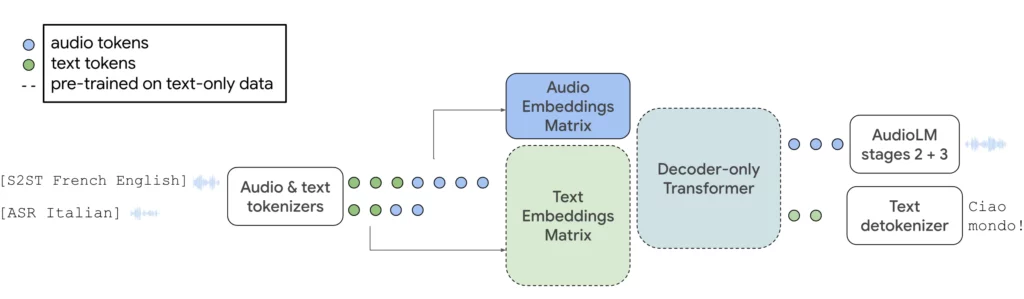
AudioPaLMにより、グーグルは5月に発表したPaLM-2大型言語モデルとAudioLM生成音声モデルをコアマルチモーダルアーキテクチャに統合した。このシステムは、テキストと音声を処理・生成することができ、音声認識やオリジナルの音声による翻訳生成に使用することができる。
バベルフィッシュに迫る
特に注目すべきは後者の機能で、以下のデモが示すように、一人の人間が複数の言語で同時に話すことができる。
元の音声の条件付けには、音声とSoundStreamトークンとして提供される3秒間のサンプルだけが必要です。オーディオファイルが短い場合は、3秒になるまで繰り返されます。
AudioLMを統合することで、AudioPaLMは長期的な一貫性を持った高品質のオーディオを生成することができます。これには、トレーニング中に見られなかった話者の同一性と韻律を保持しながら、意味的にもっともらしい音声の続きを生成する機能が含まれます。
また、このモデルは、トレーニング中に遭遇しなかった音声の組み合わせを含む多くの言語において、事前のトレーニングなしに音声からテキストへの翻訳を行うことができます。この機能は、リアルタイムの多言語コミュニケーションなど、実世界のアプリケーションにとって重要です。
AudioPaLMはまた、話者の同一性やイントネーションなど、従来の音声テキスト翻訳システムでは失われがちなパラ言語情報を保持することができる。このシステムは、自動評価と人間による評価に基づき、音声品質の点で既存のソリューションを上回ることが期待される。
音声生成に加え、AudioPaLMは、原語または直接翻訳として書き起こしを生成したり、原語の音声を生成したりすることもできる。AudioPaLMは、音声翻訳ベンチマークでトップクラスの結果を達成し、音声認識タスクでも競争力のある性能を発揮しています。
音声アシスタントから自動多言語化へ
多言語音声アシスタント、自動テープ起こしサービス、その他、人間の書き言葉や話し言葉を理解したり生成したりする必要のあるシステムなど、潜在的な用途は多い。
グーグルは、特にユーチューブにおいて、AIが生成する多言語ビデオのユースケースを見つけることができるだろう。例えば、多言語字幕を作成したり、元の話者の声を失うことなくビデオを多言語にダビングしたりするのに役立つだろう。
研究者たちは、音声トークンの最適な特性を理解し、それを測定して最適化する方法など、今後の研究分野をいくつか指摘している。また、この分野の研究をさらに加速させるために、生成音声タスクのための確立されたベンチマークと測定基準の必要性も強調している。
より詳細な情報とデモは、プロジェクトのGitHubページで入手できる。
