
FinGPTは、金融タスクに最適化された言語モデルへのアクセスを容易にするために設計されたAIフレームワークである。オープンソースであり、商用利用も可能である。
FinGPTによって、コロンビア大学とニューヨーク大学(上海)の研究チームは、金融市場に最適化された言語モデルへのアクセスを民主化することを目指している。
BloombergGPTのような独自モデルは、ユニークな金融データへのアクセスから利益を得ることができる、と研究者たちは主張する。さらに、BloombergGPTはトレーニングに500万USドルもかかり、柔軟性に欠けるという。
その代わりに、FinGPTは事前に訓練された言語モデルを利用し、低ランク効率適応(LoRA)法を用いて微調整を行う。同チームによると、LoRA法は学習可能なパラメーターの数を61億7000万からわずか367万に減らすことができるという。これにより、微調整プロセスが大幅に高速化され、計算負荷が軽減されるとともに、モデルが金融テキストを効率的に理解し、出力できるようになる。
高品質のデータストリームに集中
研究者らは、金融言語モデルの成功は、言語モデルの能力とデータの質の両方にかかっていると主張している。研究チームは、FinGPTをBloombergGPTに直接対応するものと考えているため、データの品質と準備に重点を置いている。
チームはまず、厳選された高品質の金融データの自動パイプラインを開発した。ヤフーファイナンスやブルームバーグといった定評のある情報源に加え、ツイッター、レディット、SEC(米証券取引委員会)提出書類といったプラットフォームからのコンテンツも活用している。また、Google Trendsのようなトレンド指標や、AShareやStocknetのような連結データセットからも情報を入手している。
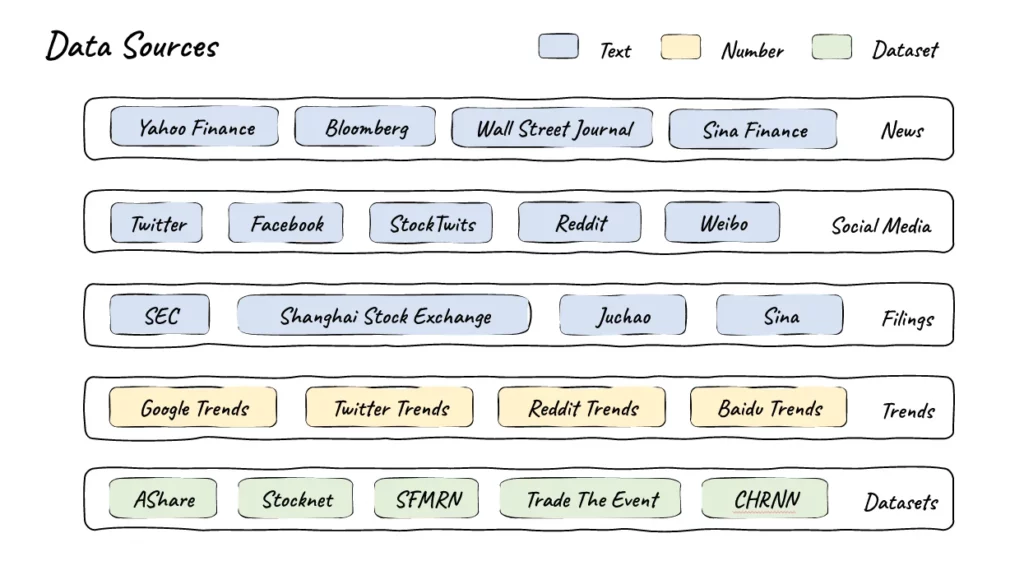
同チームによると、このデータは、品質と使いやすさを確保するため、包括的なクリーニングとフォーマット処理が行われる。
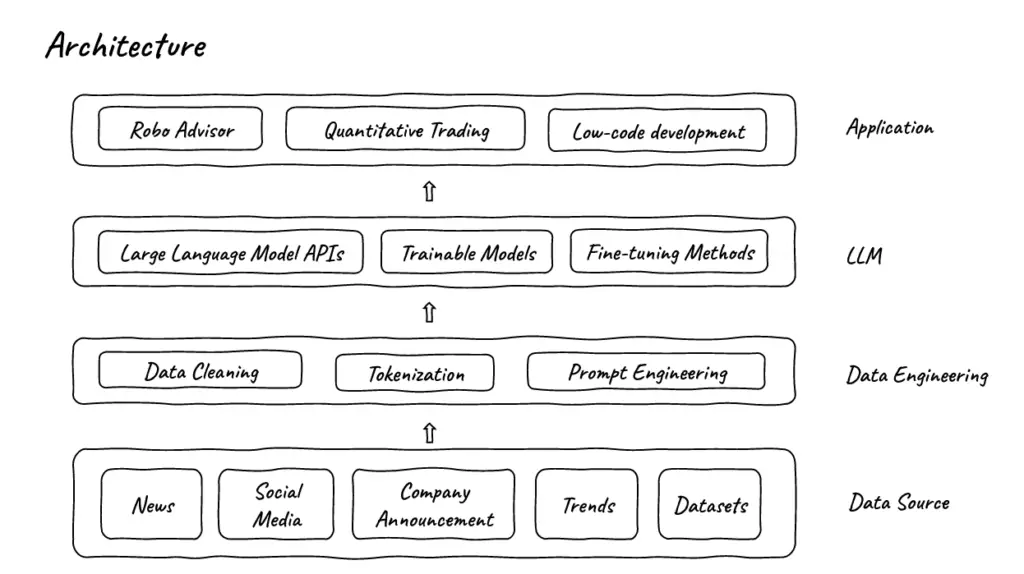
その後、データはFinGPTフレームワークを使用して言語モデルで処理される。用途に応じて、有名企業のLLM(学習言語モデル)を使用することもできるし、カスタマイズしたデータで学習可能なモデルや調整可能なモデルを強化することもできる。モデルを完全に訓練するよりも微調整の方が速いため、FinGPTはBloombergGPTよりも最新かつダイナミックだと言われている。
偏差を通じた人間によるフィードバックの自動化
モデルの微調整には通常、大量の高品質なラベル付きデータが必要です。ラベル付けされたデータとは、あるニュースが良いとされるか悪いとされるかといった、モデルが学習するための追加情報を含むデータのことである。このようなデータの入手は、特に金融のような特殊な分野では困難で高価な場合があります。
そこでFinGPTチームは、データを手作業でラベル付けする代わりに、ニュースに対する株式市場の反応をラベルとして使用するというエレガントな解決策を思いついた。例えば、あるニュースの後に株価が上昇した場合、「ポジティブ」と分類することができる。
研究者たちは、ポジティブ、ネガティブ、ニュートラルの3つの感情にしきい値を設定した。モデルをフィッティングする際、ポジティブ、ネガティブ、ニュートラルの3つのセンチメントのうち1つをニュースのラベルとして選択するよう指示する。
OpenAIのRLHF(人間のフィードバックによる強化学習)アプローチに従って、研究者たちは自分たちの原理をRLSP(株価に関する強化学習)と呼んでいる。このシステムは、金融市場をよりよく理解し予測するために、「市場の知恵」から学ぶ必要がある。
金融分野におけるAIのオープンソース・フレームワーク
研究チームは、FinGPTフレームワークの応用例として、ロボアドバイザー、クオンツ取引、様々な要因に基づくポートフォリオの最適化、金融市場におけるセンチメント分析、リスク管理、詐欺検出、クレジットスコアリング、倒産や買収の可能性の予測、公的レポートやニュースに基づくESGプロファイルの分析、ローコード開発、金融教育などを挙げている。
研究者らは、FinGPTをGithubのMITライセンスの下でオープンソースとして公開している。商用利用は許可されている。開発者は、このモデルに基づく金融判断について保証も責任も負わない。デコーダーのコンテンツを含む。
