
クラウドマーケティング企業Salesforceの複雑なプロンプトは、GPT-4を使用して記事の要約の品質を向上させることを目指しています。
「密度の連鎖」プロンプトでは、ますます詳細な要素を持つ要約の初稿をできるだけ少なくして作成するように、まずGPT-4に指示します。次のステップでは、この要約を見直し、さらに詳細を追加するようにGPT-4に指示します。
連想の鎖のプロンプトと同様に、モデルは最初に生成された出力を次世代のモデルとして使用します。モデルがこのプロセスを何度も繰り返すほど、同じ文字数の要約に情報密度が高くなります。
「CoDによって生成された要約は、通常のGPT-4のプロンプトによって生成された要約よりも抽象的で、より多くの情報が統合され、バイアスが少ない」とチームは述べています。
Article: {{article}
You will generate increasingly concise entity-dense summaries of the above article. Repeat the following 2 steps 5 times.
Step 1: Identify 1-3 informative entities (delimited) from the article which are missing from the previously generated summary.
Step 2: Write a new denser summary of identical length which covers every entity and detail from the previous summary plus the missing entities.
A missing entity is
- Relevant: to the main stories.
- Specific: descriptive yet concise (5 words or fewer).
- Novel: not in the previous summary.
- Faithful: present in the article.
- Anywhere: located in the article.
Guidelines:
- The first summary should be long (4-5 sentences, ~80 words), yet highly non-specific, containing little information beyond the entities marked as missing. Use overly verbose language and fillers (e.g., "this article discusses") to reach ~80 words.
- Make every word count. Rewrite the previous summary to improve flow and make space for additional entities.
- Make space with fusion, compression, and removal of uninformative phrases like "the article discusses".
- The summaries should become highly dense and concise, yet self-contained, e.g., easily understood without the article.
- Missing entities can appear anywhere in the new summary.
- Never drop entities from the previous summary. If space cannot be made, add fewer new entities.
Remember: Use the exact same number of words for each summary.
Answer in JSON. The JSON should be a list (length 5) of dictionaries whose keys are "missing_entities" and "denser_summary".
ビルド:Salesforce
要約の複雑さ
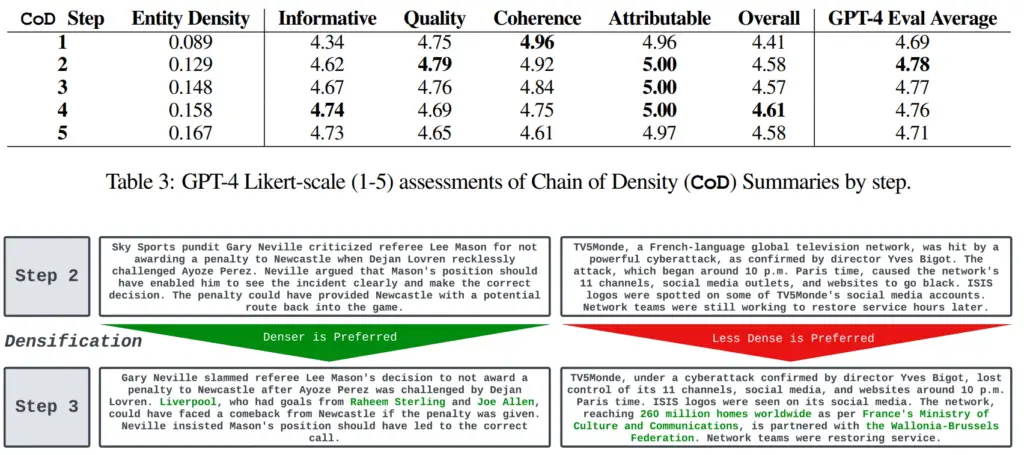
研究チームはCNNとDailyMailからの100本のニュース記事でこのプロンプトをテストしました。この場合、著者の4人を含む人間のレビュアーが約3回のパスの後に最高の評価をつけました。
平均して、GPT-4は2回のパス後に情報、品質、整合性、帰属、および「全体的に」最も高く評価されたとされています。 CoDメソッドは、テストされたより単純なプロンプト(「記事の非常に短い要約を書いてください。 70語を超えないでください。」)を上回ると言われています。
「要約に多くのエンティティがトークンごとに含まれている場合、ある程度の密度が望ましいことがわかりました。ただし、読みやすさと整合性を維持することは非常に難しい」とチームは記しています。
ビルド:Salesforce
全体的に、最初と最後のステップが最も低いスコアを取り、中間の3つの要約が近いスコアを取ります。要約の最初のスコアが低いのは、プロンプトがモデルに最初に浅い要約を書くように指示しているため、理にかなっています。
結果が非常に近いことは、一定のレベル以上のテキストを評価することが難しいことを示しています。これにより、即時のエンジニアリングの影響を測定することが難しくなります。
研究チームは、CoDのアノテーションされた500の要約とアノテーションされていない5000の要約のデータセットをプロンプトと一緒に公開しています。
