
3D-LLMは、大規模な言語モデルに3D環境の理解を統合し、チャットボットを2次元の世界から3次元の世界へと導きます。
大規模な言語モデルやマルチモーダルな言語モデルは、ChatGPT、GPT-4、Flamingoなど、音声や2D画像を扱うことができます。しかし、これらのモデルは3D環境や物理空間の本当の理解に欠けています。研究者たちは、この問題を解決するために3D LLMsと呼ばれる新しいアプローチを提案しました。
3D LLMsは、3Dデータ(ポイントクラウドなど)を入力として使用して、AIに3次元空間の概念を提供するように設計されています。これにより、マルチモーダルな言語モデルは、2D画像だけでは理解が難しい空間的な関係、物理的な特性、および利用可能性などの概念を理解することができます。3D LLMsは、ロボティクスや組み込みAIなどの3Dの世界で、AIアシスタントがより良くナビゲートし、計画し、行動することを可能にするかもしれません。
世界と言語の間の関係
モデルを訓練するために、チームは十分な数の3Dと自然言語のペアのデータを収集する必要がありました。このようなデータセットは、ウェブ上で利用可能な画像とテキストのペアと比べて限られています。そのため、チームはChatGPTに対して刺激的な技術を開発し、異なる3Dの記述や対話を生成することができるようにしました。
その結果、3Dテキストの300,000以上の例を含むデータセットが生成されました。これには3Dのラベリング、視覚的な質問への回答、タスクの分解、およびナビゲーションなどのタスクが含まれます。例えば、ChatGPTには、異なる角度から見えるオブジェクトについての質問をして、3Dの寝室のシーンを説明するよう依頼されることがありました。

訓練のために、チームはChatGPTを使用して大規模なデータセットを生成しました。| 画像:Hong et al.
チームは、テキストの説明を3D空間の点に関連付けました。
そして、彼らは3D特徴抽出器を開発しました。これにより、3DデータをBLIP-2やFlamingoなどの2Dビジョンで事前トレーニングされた言語モデルと互換性のある形式に変換できるようになりました。
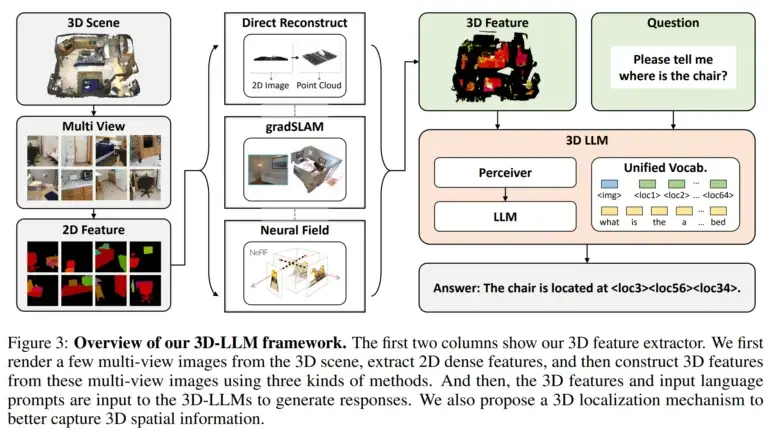
さらに、研究者たちは3Dの空間情報を取り込むための3Dロケーションメカニズムを利用しました。このメカニズムにより、モデルはテキストの説明と3Dの座標を関連付けることで、空間情報をキャプチャできるようになりました。これにより、BLIP-2などの2Dビジョン向けに事前学習されたモデルを効率的に活用し、3D LLMsを3Dシーンを理解するようにトレーニングすることが容易になりました。
3D言語モデルのテストは有望な結果を示しました
実験では、3D言語モデルが3Dシーンの自然言語による説明を生成し、3Dに意識した対話を行い、複雑なタスクを3Dのアクションに分解し、言語と空間的な位置を関連付けることができることが示されました。これにより、人間のような空間認識能力を組み込んだ、3D環境に対するより人間らしい知覚の開発に人工知能の潜在能力が示されました。
研究者たちは、これらのモデルを音など他のデータのモダリティにも拡張し、さらに追加のタスクを実行するようにトレーニングする計画です。また、彼らはこれらの進展を3D環境とインテリジェントに対話することができる組み込み型AIアシスタントに応用することを目指しています。The Decoderの情報を使用しています。
