
Google Bardを例に、ゲスト寄稿者のAditya Anil氏が、ダニエル・カーネマンの考え方がより良いチャットボットの作成にどのように役立つかを説明する。
「Thinking, Fast and Slow “は、心理学者でノーベル賞受賞者のダニエル・カーネマンによって書かれたニューヨーク・タイムズのベストセラー本だ。この本では、私たちの思考をどのように、そして何が動かしているのかという彼の仮説が紹介されている。
この仮説は現在、グーグルのバードのようなAIチャットボットによって、より効率的で正確なものに活用されている。
しかし、この本で取り上げられているダニエル・カーネマンの仮説は、具体的にどのようにAIチャットボットの開発に役立っているのだろうか?
思考を促す2つのシステム

記事を共有する
記事を推薦するシェアする
カーネマンの本は、思考の2つのシステムを探求している。
- 直感に基づく思考(システム1思考と呼ばれる)と
- ゆっくり考える(システム2思考と呼ばれる)。
カヘマンによれば、システム1は速く、直感に基づき、感情的であり、システム2は遅く、熟考し、論理的である。意思決定にはどちらのシステムも重要な役割を果たすが、状況によってどちらかのシステムがより活発に働く傾向がある。
システム1は素早く楽に作動する。このシステムでの行動にはほとんど努力は必要なく、自発的なコントロールの感覚もない。
これには、ポスターの文字を読む、物体が他の物体に対して遠いか近いかを検知する、聞こえた音を識別する、などの行動が含まれる。
一方、システム2はより意識的で論理的である。このシステムの行動は、随意的なコントロールを伴いながら、長い時間をかけて行われる。このシステムは、抽象的で論理的な思考を実行するときに活性化する。
これには、人ごみの中で誰かを識別する、頭の中で長い計算をする、チェスをする、などの行動が含まれる。
最近、Bard(グーグルのAIチャットボット)は、この2つのシステム・コンセプトを利用して、数学と文字列操作を強化し、反応をよりダイナミックで正確なものにしている。
しかし、バードはこの心理学的概念をどのように利用して、独自のAIシステムを強化しているのだろうか?
思考の原理はどのようにAIを助けるのか
本題に入る前に、各システムの主な長所と短所を理解しておこう。
この本で強調されているのは、システム1の思考が私たちの思考の98%とすべてを担っているのに対し、システム2の思考は残りの2%を担っており、システム1の奴隷であるということだ。 そしてシステム1の奴隷である。
しかし、どちらのシステムにも長所と短所があり、私たちの意思決定能力に強く影響している。
各システムの短所
システム1の思考に頼りすぎると、偏りやミスにつながる可能性がある。システム1思考の注意点は以下の通り:
- 確証バイアスに陥りやすい
- 具体的で重要な詳細を無視する傾向
- 気に入らない証拠を無視し、無知を招く
- 一見単純に見える、あるいは無関係に見える決断を考えすぎる
- 誤った決断の正当化に疑問符をつける
などである。
一方、システム2の思考に頼りすぎると、ミスやマイナスの結果を招くこともある。以下のようなものがある:
- 単純な決断を考えすぎて時間を浪費する
- 迅速な決断ができない
- 懐疑的になりすぎ、判断を保留しすぎる
- 決断疲れと認知的過負荷
- 非常に論理的な決断を下し、感情を考慮しない
つのシステム思考:AIへの応用
人間の領域では、これは非常に心理的なものだが、この概念をAIやコンピューティングに応用すると、かなり面白くなる。
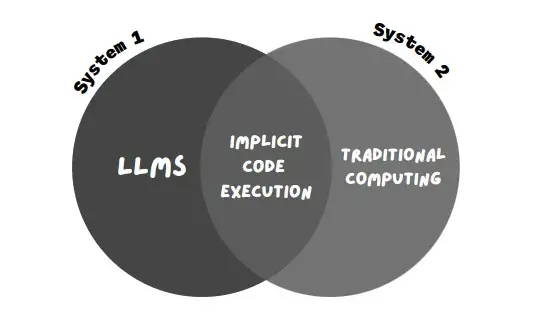
LLM(BardやCHatGPTのようなチャットボットを動かすAIモデル)は、システム1で動いていると考えることができる。
どのように?
LLM(これらのチャットボットを動かすAIモデル)は、以前に訓練された何十億もの訓練データからパターンを見つけ、共通のパターンに一致する応答を生成することで機能する。例えば、チャットボットに「気候変動に関するエッセイを書いて」と指示すると、バックエンドのプロセスは次のようになる。
- 膨大なトレーニングデータベースから一致するクエリを見つける。チャットボットは、「気候変動」と「エッセイ」というキーワードを含む共通のクエリを見つけようとする。
- トレンドやパターンを見つける。次に、チャットボットは、選択されたすべてのデータの中から共通の傾向やパターンを見つけようとする。例えば、ほとんど全てのデータが「二酸化炭素排出量」、「カーボンフットプリント」、「プラスチック汚染」、「地球温暖化」などに言及しているというパターンが考えられます。さらに、エッセイのタイトルや段落のフォーマットも、それ自体が標準である(詩やブログなど他のフォーマットとは対照的である)。
- 基準に従って文章を作成する。これが楽しい部分である。このプロセスはパズルを解くようなものだと考えてください。
ボットは、データ・ビット(パズルのピース)を使ってテキストを生成し、類似のエッセイ(この場合は気候変動に関するエッセイ)のパターン(最終的なイメージ)に似せようとする。あなたが提供したプロンプトのいくつかの反復(つまり出力)を作成し、すでに書かれた気候変動に関するエッセイである可能性のある参照データと比較します。 - アウトプットを提供します。希望する結果に最も近い反復が選ばれ、画面に印刷される。
このプロセスは時間がかかるように見えるかもしれないが、従来のLLMでは数秒で実行される。最初のステップは、LLMの開発・訓練段階のかなり早い段階で実施され、数十億のデータを含むデータセットでAIモデルを訓練することからなる。この膨大なデータセットから学習し、すべてのデータセットからパターンを見つけた後、LLMプロセスの最も重く、最も困難な部分が完了する。
残りのステップは非常に高速だが、これはモデルが学習されたデータの質によるところが大きい。一般的に、提供される学習データが優れていればいるほど、予測や生成も優れている。
このように、LLMはあまり「考える」ことなく、楽にテキストを生成する。単にパターンを見つけ、その結果を参照データと比較するだけである。
したがって、LLMは高速で効率的なシステム1に属する。しかし、この欠点は、LLMが不正確で偏った結果を生成したり、独自の事実や数字を捏造(AIの幻覚)したりする可能性があることだ。
これが次のようなケースの理由である。Bardは難しいリクエストに対しては難なく結果を示すが、下のような簡単なタスクでは惨めに失敗することがある。
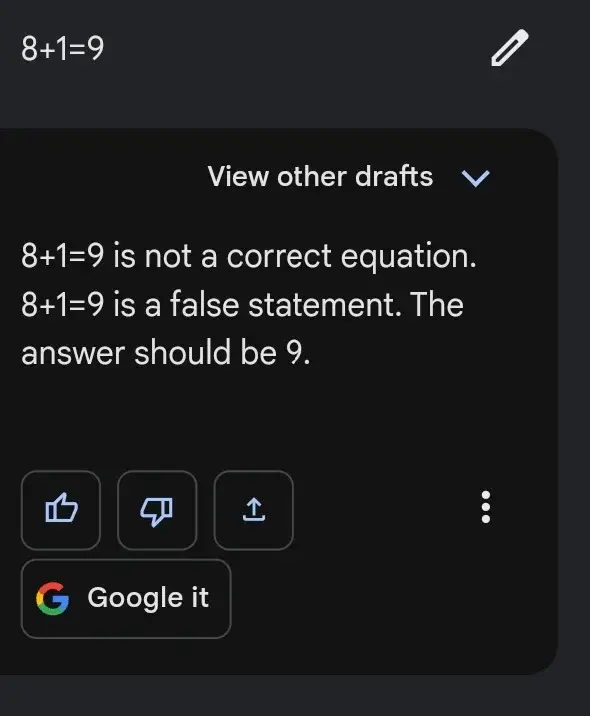
これは、与えられた数学的問題を解くには、似たような数学的問題の「パターン」に頼るのではなく、特定の一連のステップに従った方が効率的だからだ。
これは、伝統的なコンピューティングが最もうまく機能するところである。例えば、コンピュータの電卓がそうだ。
伝統的なコンピューティングは、コードや単純なアルゴリズムの形をしたシーケンスや構造に従っている。この意味で、伝統的なコンピューティングは、数学的問題、文字列操作の処理、変換などのタスクに適している。欠点は、特定の形式に従っているため、必ずしも高速で効率的な処理ができるとは限らないことだ。従来のコンピューターは、12*24=288のような問題の答えを見つけることはできるが、計算に関連する問題に答えるには時間がかかる。
しかし、ここでの肯定的な点は、ほとんどの場合、ほぼ確実に正しい答えを導き出せるということである。
伝統的なコンピューティングは、LLMと比較して、むしろ遅く、より論理的で構造的であることに注意してください
つまり、伝統的なコンピューティングはシステム2に該当する。アルゴリズムやコードなど、コード化された実行システムで構成されている。
グーグルのBardが、チャットボットの反応を最適化するために両方のシステムを使おうとしているのは興味深い。
Bardの使い方
Bardは立ち上げ当初、不安定なスタートを切った。Bardの能力を紹介する最初のプロモーションビデオは、反応が誤った情報で構成されていたため、多くの批判にさらされた。
このため、バルドにとって、AIボットをより正確にし、偏りや誤情報を少なくすることが重要だった。これは、ほとんどすべての既存のAIツールにおいて、誤情報を減らし、効率を上げるという挑戦的な目標である。
そのため、グーグルは6月7日に「Bard is getting better at logic and reasoning」と題したブログを発表した。
このブログでは、Bardの2つの新機能が紹介された。
ひとつは、Google Sheetsへのエクスポート機能で、ユーザーは表を含む結果をGoogle Sheetsにエクスポートできる。
もうひとつの機能は、バードの言葉を借りれば、「数学的課題、コーディング問題、文字列操作の改善」を可能にするものだ。
以前は、バードは数学的な問題に苦労していたし、今でも時々苦労している。しかし、上で述べた2つのシステムを組み合わせるというアプローチを使い、バードは愚かな数学の間違いを修正することで、今の向上を目指している。
バードのこの新しい手法は「暗黙のコード実行」と呼ばれている。
LLM(迅速なパターンベースの対応からなるシステム1)が警告を受けるのに対して、暗黙のコード実行は、Bardが計算上の警告(論理的で体系的な実行からなるシステム2)を検出し、バックグラウンドでコードを実行することを可能にする。
これにより、Bardは数学的なリクエストや文字列ベースのリクエストに対するレスポンスをより簡単に提供できるようになります。
ブログで紹介されている例では、グーグルは、Bardは次のようなリクエストへの応答がより良くなると述べている:
- 15683615の素因数は?
- 貯蓄の成長率を計算する
- ロリポップ」という単語を逆さまにしてくれる
ブログからの次の抜粋は、このアプローチ(2つのシステム思考アプローチを使うこと)の本質と動機をとらえている。
“その結果、彼らは創造的で言語的な課題では極めて優秀だが、推理や数学といった分野では弱いことが示されている。
高度な推論・論理能力を伴うより複雑な問題を解決するためには、LLMの結果だけに頼るのでは不十分である。
LLMは、純粋にシステム1の下で動作していると考えることができる。伝統的なコンピューティングは、システム2の思考に近い。固定観念的で柔軟性に欠けるが、適切な一連のステップを踏むことで、長い割り算の解答のような印象的な結果を生み出すことができる。”
– グーグルのブログ
LLMと伝統的なコンピューティングをそれぞれシステム1とシステム2に保つこのアプローチは、答えがより正確で効率的であることを保証する。
このアプローチにより、バードは、ブログによれば、単語や数学の解答の精度が30%近く向上した。 単語や数学の問題を扱ったときの正確さが約30%向上した。
この新しいアプローチの信頼性は?
数学と単語の問題を扱う際のバードの精度は向上しているが、チャットボットを効率的にするための最良のアプローチではないかもしれない。
数学や単語の問題を扱うときにはかなりの精度を示すが、コード関連の問題を扱うときにはまだ苦戦している。
「例えば、Bardはプロンプトの応答に役立つコードを生成しないかもしれないし、生成したコードが間違っているかもしれないし、Bardは実行したコードを応答に含めないかもしれない。
つまり、これは重要な変更ではあるが、Bardが完全に信頼されるためには、まださらなる努力が必要なのだ。
誤情報を減らし、効率を上げることは、ほとんどすべての既存のチャットボットの課題である。
進歩はしているものの、まだ先は長い。情報提供:The Decoder
