
ある意味で、人間と大規模な言語モデルは類似した行動を示すようです。特に内容の先頭や末尾にある情報に対して特によく反応します。中間の情報は失われがちです。
スタンフォード大学、カリフォルニア大学バークレー校、Samaya AIの研究者たちは、LLMs(大規模言語モデル)における効果を発見しました。これは、人間に知られている「先頭/最終の効果」と似ています。これは、人々が声明の先頭と末尾をよく覚える傾向があることを意味します。中間の内容は無視される可能性が高いです。
研究によると、大規模言語モデルでも似たような効果が現れます。入力から情報を取り出すようにモデルに要求された場合、情報が入力の先頭や末尾にある場合、モデルのパフォーマンスが向上します。
ただし、関連情報が入力の中間にある場合、パフォーマンスが著しく低下します。特に、複数のドキュメントから情報を抽出する必要がある質問に対してモデルが回答を試みる場合、このパフォーマンスの低下は顕著です。これは、学生が試験で質問に答えるために複数の本から関連情報を特定する必要がある状況に相当します。
モデルが同時に処理する必要がある入力の量が大きくなるほど、そのパフォーマンスは悪化する傾向があります。これは、重要な情報を大量に同時にかつ公平に処理することが重要な現実のシナリオで問題になる可能性があります。
この結果はまた、大規模な言語モデルが追加情報をどれだけ効果的に利用できるかには限界があること、そして特に詳細な指示を含む「メガプロンプト」はおそらく悪い結果をもたらす可能性が高いことを示唆しています。
大きなコンテキストウィンドウを持つLLM(Large Language Models)はどれだけ有用ですか?
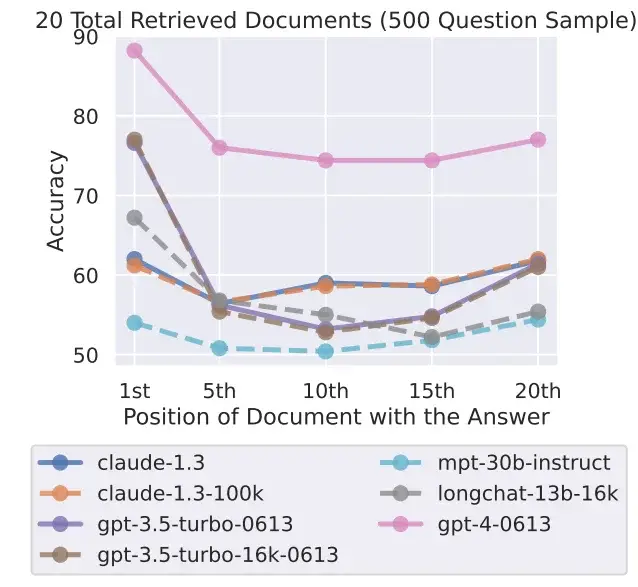
「中間での損失」現象は、GPT-4 32KやClaudeなど、多くのコンテキストを処理するために特に設計されたモデルでも発生します。
研究者たちは、新しいGPT-3.5 16KやClaude 1.3などを含む、7つのオープンおよびクローズドな言語モデルをテストしました。すべてのモデルは、テストに応じてよりまたはより少なくU字型のカーブを示し、テキストの先頭または末尾に解決策があるタスクでより優れたパフォーマンスを示しました。

これは、より小さいコンテキストを処理することでより良い結果が得られる場合に、大きなコンテキストウィンドウを持つモデルの有用性についての問題を提起します。現在のトップモデルであるGPT-4でも、この効果が見られますが、全体的なパフォーマンスレベルがより高いです。
研究チームは、現在のところ、言語モデルがどのように処理されるかについて完全に理解されていないと認識しています。新しい評価方法によりこの理解を向上させる必要があり、新しいアーキテクチャも必要になるかもしれません。
研究者たちはまた、プロンプトのデザインがモデルのパフォーマンスにどのように影響するかを調査する必要があると述べています。プロンプトに対するタスク意識を高めることで、関連情報をよりうまく抽出する能力を向上させることができる可能性があります。
