
グーグルは先週、AIを搭載した新しい検索ツールを一部のユーザーに公開した。良いニュース?グーグルの新しい検索は、ChatGPTのような他の競合AIツールよりも正確な回答を提供する。悪いニュースは?より正確な理由は、グーグルのAIがインターネットから情報をコピーしているからだ。さらに悪いことに、グーグルの新しい検索デザインはオンライン出版業界を破滅させる可能性が高い。
OpenAIのChatGPTは2022年後半に一般公開され、生成的AIと呼ばれる、権威ある声で会話調に質問に答えることができるチャットボットのゴールドラッシュを引き起こした。しかし、ChatGPTを使ったことのある人ならわかるように、あまり正確ではない。実際、ChatGPTは存在しない情報源を作り出しているだけだ。あるニューヨークの弁護士が、連邦裁判所に全く架空の事例を判例として記載した書類を提出した際に、このことを痛感した。
グーグルは、OpenAIに追いつくために何年も開発を続けてきたBardと呼ばれる競合チャットボットを発表したが、最近グーグルは、間違いなくインターネット全体で最も重要な製品である、世界の検索エンジン市場の約94%を占めるグーグル検索に、まもなくジェネレーティブAIを組み込むと発表した。
週末にこのグーグル検索の新バージョンを使ってみて、私はこれがウェブ上で人々が情報を得る方法に革命を起こすと心から信じている。しかし、この新技術が一般に展開されると、多くのオンライン出版社は苦戦を強いられることになると思う。今月初め、グーグルがカリフォルニア州マウンテンビューで開催された同社の年次開発者会議で計画を発表したとき、私はすでにこのことを主張していた。
グーグルの新しい検索機能にアクセスした後、私は単純な質問をした。するとグーグルは、答えがありそうなさまざまなサイトへの青いリンクが張られた従来のグーグル・ページを表示する代わりに、下のスクリーンショットにあるように、私の質問に答えるために3段落のテキストを作成した。
デザイン的にも見栄えがよく、わかりやすい回答だった。グーグルの回答はどの程度正確でしたか?私が見た限り、非常に正確でした。しかし、なぜ正確なのかは、一部の人々にとっては深刻な倫理的問題を引き起こすだろう。
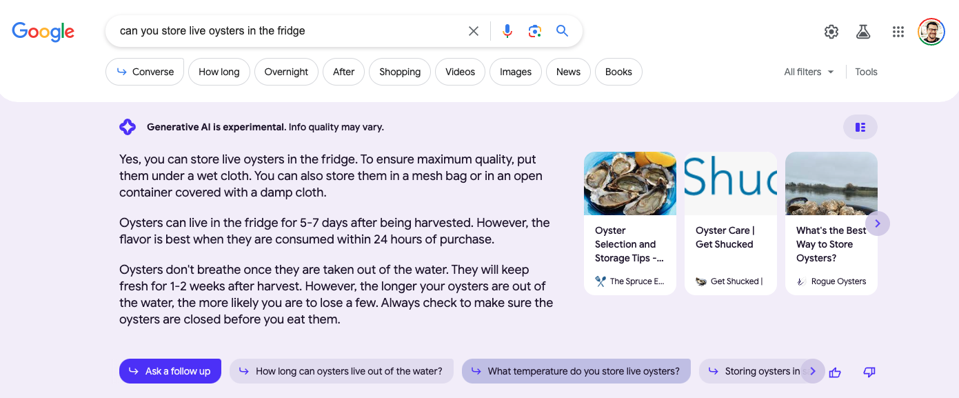
ご覧のように、グーグルの回答の最初の行にはこうある。最高の品質を保つには、湿らせた布の下に置いてください “とある。グーグルはこの情報をどこから得たのか?Get Shuckedというブログからで、そこには次のような一文がある:”You can keep live oysters in the fridge.最大限の品質を確保するには、湿らせた布の下に置いてください “という一文がある。Googleは “yes “という単語を追加し、”store “という単語を “keep “に入れ替えたようだ。
はっきり言って、グーグル検索が情報をどこから得ているのかを透明にしているのは良いことだ。右側に表示されている3つのサイトは、クリックすると詳細情報を見ることができる。実際、小さな矢印をクリックすると5つのリンクがある。しかし、100万ドルの問題は、これらのサイトがGoogleのために価値を創造している以上、これらのサイトが自らの収益を生み出すために、誰かが実際にこれらのリンクをクリックするかどうかということだろう。
牡蠣に関するグーグルの回答の3行目には、「メッシュの袋に入れたり、湿った布で覆ったオープンな容器に入れて保存することもできます」と説明されている。この行は、Spruce Eatsというウェブサイトからの引用のようで、”湿った布で覆われたメッシュバッグやオープンコンテナで梱包する必要があります “と書かれている。ここでもいくつかの単語が入れ替わっているが、それ以外は同じ文章である。
グーグルの回答の最後の数行は、Oysters XOというブログから直接コピーしたものである。グーグルの回答がサイトから一字一句コピーされたことを示す簡単な図を作ってみた。下線が引かれていない部分は、他のサイトに掲載されているものと非常によく似ているが、完全なコピーではない。グーグルのAIは、たとえば「メンテナンス」の代わりに「ストア」のような類義語を代用したようだ。しかし、このような答えを提出した高校生は、おそらく盗作で落第するだろう。

このグーグルの新しい検索実験には、プラスもマイナスもある。グーグルのアドバイスに従えば、牡蠣を冷蔵庫で保存しても大丈夫だろう。しかし、グーグルのアドバイスが正確である理由は、すぐにネガティブな側面に行き着く。それは、ウェブサイトからのコピーに過ぎず、人々が実際にそのサイトを訪問するインセンティブを提供しないことである。
なぜこれが重要なのか?なぜならグーグル検索は、大手新聞社であれ小さな独立系ブログであれ、大多数のオンラインパブリッシャーにとって最大のトラフィックジェネレーターだからだ。そして、グーグルの最も重要な製品へのこの変更は、すでに減少している収益をさらに台無しにする可能性がある。
私の牡蠣に関する質問の場合、グーグルのAIが生成した回答で必要な情報はすべて得られた。グーグルのホームページを離れることなく、ネット上のブログから抜粋された重要な情報をすべて得ることができたのだ。昔なら(つまり、新しい実験にアクセスできない人々のためにグーグルが現在存在しているように)、私はおそらく、冷蔵庫で牡蠣がどれくらい生き延びることができるかを知るために、グーグル検索で上位のブログのひとつをクリックしただろう。しかし、今は何もクリックする必要はない。そして問題は、グーグルがオープンウェブからすべての情報を吸収し、すべてのユーザーに半盗作された形で返すだけなら、わざわざそうする人がいるかどうかということだ。
オンライン出版社は、人々が自分たちの記事をクリックしてくれるかどうかに依存している。購読料を売るか、広告主に目玉を売るかのどちらかだ。しかし、この新しい形のグーグル検索が、過去20年間と同じようなトラフィックを生み出すかどうかは不明だ。
グーグルの新しい検索ツールは、どの検索でもトップに非常に目立つように警告が表示されるように、まだ実験的なものだ。そして、グーグルは人種差別的、性差別的なコンテンツに対する回答を生成しないように、いくつかの安全策を講じているようだ。例えば、人種差別は本当にあるのかと質問したところ、AIは答えようとしなかった。woke(目覚めた)」という言葉の意味を尋ねると、「AIによる概要はこの検索では利用できません」というフレーズが返ってきた。
しかし、グーグルの新しい検索が、私にとって意外な質問に答えてくれない分野もある。グーグルにエイリアンの存在について質問したが、答えは返ってこなかった。エリア51や、政府を動かしている空飛ぶ円盤の存在や逆さ吸血鬼について、グーグルは何を隠しているのだろうか?
グーグルの検索には、ユーザーが何もクリックしなくてもすぐに答えが出るようにすでにデザインされているものもある。例えば、”デヴィッド・ボウイは何歳で亡くなったのか?”という質問を検索すると、下のスクリーンショットにあるように、グーグルが提供する答えは従来からもっとわかりやすいものだった。AIが生成した故ミュージシャンに関する答えは、従来のグーグル検索がすぐ下に表示したのと同じように、答えを強調することはなかった。

他の比較的無害な質問も、新しいグーグル検索機能では答えにくかった。中世の人々は静電気についてどう考えていたのだろうか?中世の人々は静電気についてどう考えていたのだろうか?呪術の証拠だと信じていたのだろうか、神からの軽い罰だと信じていたのだろうか、それともこの奇妙な自然現象を説明する何か他の力だと信じていたのだろうか?グーグルのAIはつまずき、AIでは答えを生成できないと言った。そこで私は、植民地時代のアメリカ人が静電気についてどう考えていたかを尋ねてみた。AIは結果の一番下に、紀元前600年にさかのぼる答えを生成したが、それ以外の答えはすべて、より一般的な静電気に関するものだった。
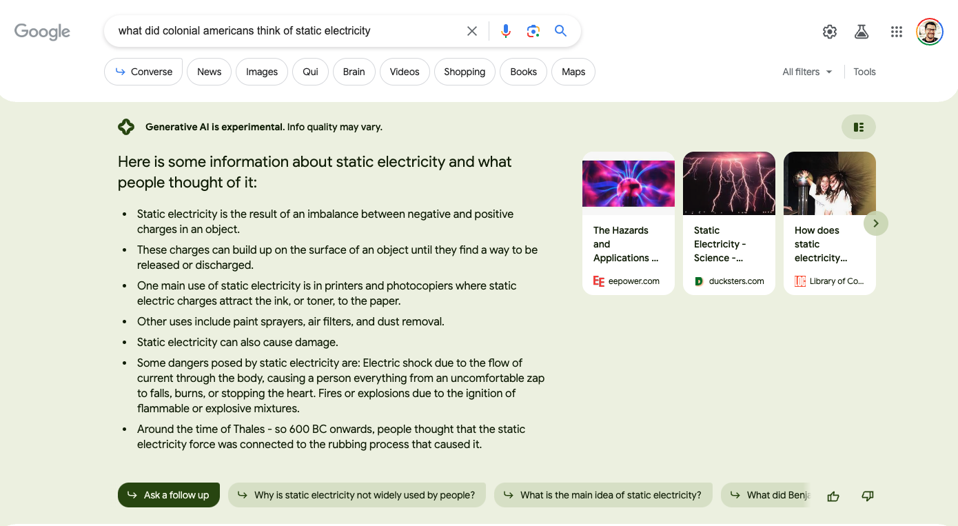
私のように答えが気になる人は、2017年の教科書に、中世の手品師が静電気を利用して手品をすることがあったという記述があったので、納得がいく。しかし、数百年前の一般人が静電気ショックについてどう考えていたかについては、まだ詳しい答えは得られていない。昔の人々が静電気についてどのように考えていたかをもっと知りたければ、珍しい質問に答えるためによく必要なように、グーグル検索だけでなく、もっと突っ込んだ調査をする必要がある。
過去の人々が静電気についてどのように考えていたかを調べるために本や雑誌の論文を検索した後、私はそれについてPalaeofutureブログに書くだろう。しかし、グーグルの検索能力に関する中心的な疑問に戻ってくる。グーグルは、私が書いた記事を自分の目的のために盗用するのだろうか?つまり、グーグルのAIツールは私の記事から3つの段落を抜き出し、ユーザーが私のウェブサイトにアクセスすることなくそれを再現するのだろうか?
Palaeofutureが存続しているのは、有料購読者がいるからだ。しかし、ソーシャルメディアやグーグルなどの検索エンジンでサイトを見つけてもらって初めて、有料会員を獲得することができる。他のサイトには広告もあり、これも実際にリンクをクリックして記事を読んでもらうことに依存するビジネスモデルだ。そして、グーグルの新しい検索ツールは、パブリッシャーが受け取るオンライン・ビューの数を激減させると思われる。私は数週間前にこのことを主張したが、グーグルの新しい検索機能を試してみた結果、この主張は正しいと思う。
グーグル側としては、私が体験していることは実験であり、大々的なローンチの前に変更される可能性があると強調している。
「SGE(新しい検索エンジンの実験)では、サイトにスポットライトを当て、ウェブ全体のコンテンツに注目を集めることを目標としています。そして、スクリーンショットの一部に特定のソースからのコンテンツが含まれている場合、そのソースをスクリーンショットの中で目立つようにハイライトします。
「スクリーンショットの各部分にどのようにリンクが適用されているかは、拡大して確認することができます。SGEは、Search LabsとSearch Evolutionにおける実験的な試みであり、何が人々にとって最も有益かを学ぶためのものです」と広報担当者は続けた。
同社はまた、私が見ていた、段落全体を一字一句コピーした結果を軽視し、それを「スニペット」と呼んだ。しかし、私が強調した文章は、単純なスニペットよりもインターネットから広く引用していることを示していると思う。繰り返しになるが、すべては人々が実際にリンクをクリックするかどうかにかかっている。
グーグルは、インターネット上で価値ある情報を提供している多くのパブリッシャーを排除するのだろうか?時間が経たなければわからない。しかし、この新しい生成AIツールが大衆に浸透すれば、オンラインパブリッシャーのトラフィックは大きく落ち込むだろう。そして奇妙なことに、グーグルは新製品を成功させるために、同じパブリッシャーを必要としている。グーグルは過去20年間、世界中の情報を吸収することに費やしてきた。そして今、グーグルは唯一無二の回答マシンになろうとしている。
フォーブスの記事より
