
FalconLMオープンソース言語モデルは、MetaのLLaMAよりも優れたパフォーマンスを提供し、商用利用も可能です。ただし、商用利用は収益が100万米ドルを超えた場合、ロイヤリティ支払いの対象となる。
FalconLMは、アラブ首長国連邦のアブダビにあるTechnology Innovation Institute(TII)によって開発されている。同組織は、FalconLMはこれまでで最も強力なオープンソース言語モデルであると主張しているが、最大のバリエーションである400億のパラメータは、650億のパラメータを持つMetaのLLaMAよりもかなり小さい。
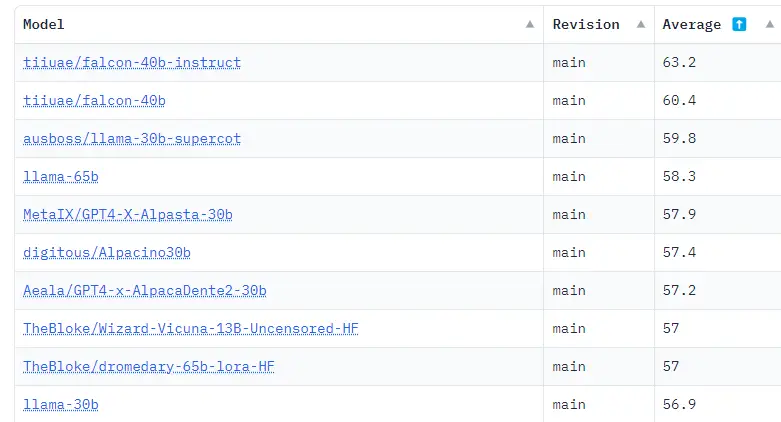
様々なベンチマークの結果をまとめたHugging Face OpenLLM Leaderboardでは、2つの最も大きなFalconLMモデル(そのうちの1つはインストラクションで改良されている)が、現在、大きな差をつけて上位2位を占めている。TIIは70億パラメータモデルも提供している。
FalconLMはGPT-3よりも効率的にトレーニングする
開発チームによれば、FalconLMの競争優位性の重要な側面は、訓練用データの選択にある。言語モデルは訓練中のデータの質に敏感である。
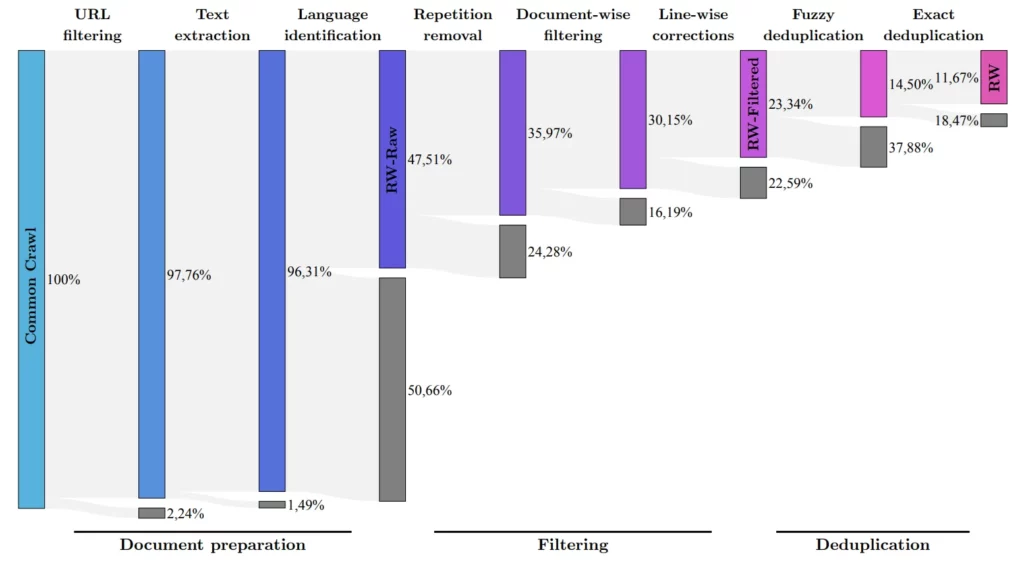
研究チームは、よく知られたCommon Crawlデータセットから高品質のデータを抽出し、重複を除去するプロセスを開発した。この徹底的なクリーニングにもかかわらず、強力な言語モデルを訓練するのに十分な5兆個のテキスト断片(トークン)が残った。コンテキスト・ウィンドウは2048トークンで、ChatGPTレベルのすぐ下だ。
400億個のパラメータを持つFalconLMは1兆個のトークンで訓練され、70億個のパラメータを持つモデルは1.5兆個のトークンで訓練された。RefinedWebデータセットのデータは、科学論文やソーシャルメディア上の議論から「いくつか」選択されたデータセットで強化された。最もパフォーマンスの良いチャットボット・バージョンは、Baizeデータセットを使って改良された。
TIIは、パフォーマンスと効率を最適化したアーキテクチャについても言及しているが、詳細は明らかにしていない。論文はまだ公開されていない。
研究チームによると、最適化されたアーキテクチャと高品質のデータセットが組み合わさった結果、FalconLMは学習時にGPT-3の75の計算量しか必要としなかったが、旧来のOpenAIモデルを大幅に上回った。推論コストはGPT-3の5分の1と言われている。
オープンソースとして利用可能だが、商用利用は高価になる可能性がある。
FalconLMのTIIユースケースには、テキスト生成、複雑な問題の解決、パーソナルチャットボットとしての利用、あるいはカスタマーサービスや翻訳といった商業分野での利用が含まれる。
しかし、商用利用においては、TIIは言語モデルに起因する100万ドルの収益から利益を得たいと考えている。商業利用に興味のある方は、TIIの営業部門までご連絡ください。個人的な使用や研究については、ファルコンLMは無料です。
ファルコンLMモデルのすべてのバージョンは、Huggingfaceで無料でダウンロードできます。モデルとともに、チームは6,000億のテキストトークンを含む「RefinedWeb」データセットの一部もApache 2.0ライセンスのもとオープンソースとして公開している。このデータセットには、リンクや画像の代替テキストがすでに含まれているため、マルチモーダルな拡張も可能だという。
