
InternLMは、中国の国立AI研究所、上海AIラボが監視会社SenseTimeと提携して導入した1040億のパラメータを持つ大規模な言語モデルである。
香港中文大学、復旦大学、上海交通大学も開発に関与している。中国語のタスクでは、OpenAIのChatGPTや Anthropics Claudeを明らかに上回っている。
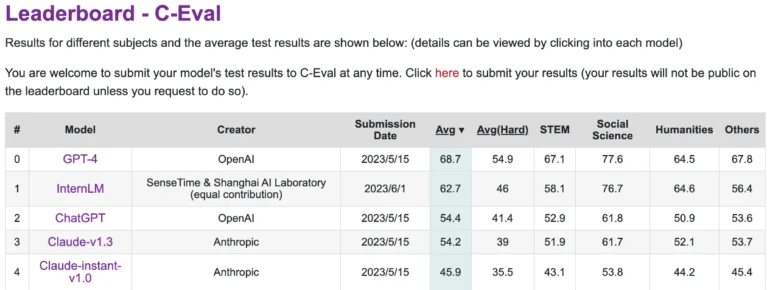
しかし、中国語の大規模言語モデルの性能を評価するプラットフォームであるC-Evalでは、GPT-4に遅れをとっている。InternLMは、1.6兆のトークンで学習され、GPT-4と同様に、RLHFと選択された例を使用して、人間のニーズを満たすように改良されています。これはGPTと同様の変換器アーキテクチャに基づいている。
訓練は主に、百科事典、書籍、科学論文、コードで強化されたマッシブ・ウェブ・テキストからのデータに基づいて行われた。また、研究者らは、2048個のGPU上で、2,000億以上のパラメータを持つ大規模な言語モデルを、一連の並列トレーニング技術を使って確実にトレーニングできるUniscale LLMトレーニングシステムを開発した。
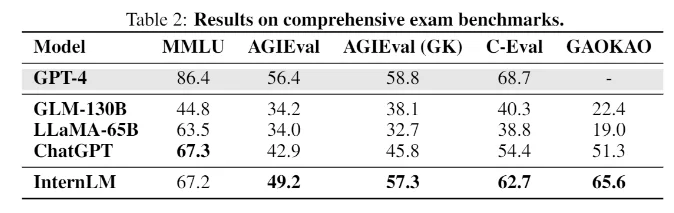
InternLMは試験ベンチマークでChatGPTと同等の性能を達成
MMLU、AGIEval、C-Eval、GAOKAO Benchなど、人間の試験をシミュレートするタスクを持つベンチマークでも、InternLMはChatGPTと同等の性能を達成しています。しかし、GPT-4には及ばず、研究者はその原因を2000トークンという小さなコンテキスト・ウィンドウに求めている。
知識検索のような他の分野では、このモデルは最高のOpenAIモデルに遅れをとっている。Meta社のLLaMAのようなオープンソースの言語モデルは、650億のパラメータを持つが、ベンチマークではInternLMを下回っている。
チームはまだ言語モデルを公開しておらず、今のところ技術文書しか入手できない。しかし、チームはGithubに、詳細は明かさないが、将来的にはコミュニティと共有する予定だと書いている。
ともあれ、InternLMは、国立AI研究所とSenseTimeがこれまでで最高の仕事をしたと仮定して、大規模言語モデリングにおける中国の研究の現状について興味深い洞察を提供している。「より高いレベルの知性に向けて、まだ長い道のりがある」と研究チームは書いている。
