
Com o PaLM-E, o Google Robotics, o TU Berlin e o Google Research apresentam um novo modelo de IA que pode entender e gerar linguagem, entender imagens e usar os dois juntos para comandos complexos de robôs.
O maior modelo do PaLM-E tem 562 bilhões de parâmetros e combina o enorme modelo de linguagem PaLM do Google com o ViT-22B, o maior transformador de visão até o momento.
The main architectural idea of PaLM-E is to inject continuous, embodied observations such as images, state estimates, or other sensor modalities into the language embedding space of a pre-trained language model.
Do paper
O maior modelo PaLM-E é capaz de processar linguagem natural de nível PaLM, ao mesmo tempo em que compreende e descreve o conteúdo da imagem e orienta os robôs por meio de etapas precisas e sequenciais, combinando linguagem e visão computacional.
Com o PaLM-SayCan, o Google demonstrou anteriormente que os modelos de linguagem podem ajudar a guiar os robôs. A abordagem de treinamento combinado do PaLM-E em todos os domínios leva a um “desempenho significativamente maior” em comparação com os modelos otimizados apenas para robótica.
É importante ressaltar que demonstramos que esse treinamento diversificado leva a várias vias de transferência dos domínios da linguagem de visão para a tomada de decisão incorporada, permitindo que as tarefas de planejamento do robô sejam alcançadas com eficiência.
Do Paper
PaLM-E consegue performar uma série de tarefas robóticas e visuais
O Google mostra outra demonstração em que PaLM-E controla um braço robótico que organiza blocos. A reviravolta aqui é que o robô processa entradas visuais e de linguagem em paralelo e as usa para resolver a tarefa. Por exemplo, ele pode mover blocos classificados por cor em cantos diferentes. O PaLM-E gera as instruções da solução passo a passo a partir da entrada visual.
De acordo com a equipe de pesquisa, o modelo também demonstra a capacidade de generalizar. No vídeo a seguir, ele guia o braço do robô para mover os blocos vermelhos em direção à xícara de café com precisão e conforme as instruções. Havia apenas três exemplos de xícaras de café nos dados de treinamento, nenhum dos quais tinha blocos vermelhos na imagem, de acordo com a equipe.
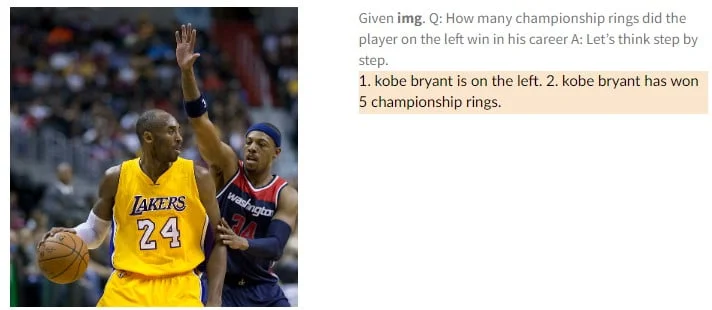
O PaLM-E também é um “modelo de linguagem de visão competente”, escrevem os pesquisadores. Por exemplo, ele reconhece o astro do basquete Kobe Bryant em uma imagem e pode gerar informações textuais sobre ele, como quantos campeonatos ele ganhou. Em outro exemplo, PaLM-E vê um sinal de trânsito e explica quais regras estão associadas a ele.

Os recursos de linguagem do PaLM-E perdem desempenho significativo devido ao treinamento multimodal e robótico nos modelos menores do PaLM-E. Esse fenômeno é conhecido como “esquecimento catastrófico” e geralmente é evitado congelando modelos de linguagem durante o treinamento. Em contraste, a queda no desempenho em comparação com o modelo PaLM maior é mínima, o que, segundo os pesquisadores, mostra que o dimensionamento pode ajudar a combater o esquecimento catastrófico.
Além disso, o maior modelo PaLM-E, com 562 bilhões de parâmetros, mostra recursos emergentes, como cadeias de raciocínio multimodais e a capacidade de raciocinar em várias imagens, mesmo que o modelo tenha sido treinado usando apenas prompts de imagem única.
Artigo inspirado na notíficia do The Decodr
