
Com o AudioPaLM, o Google está adicionando recursos de áudio ao seu grande modelo de linguagem PaLM-2. Isso permite traduções faladas com a voz do locutor original.
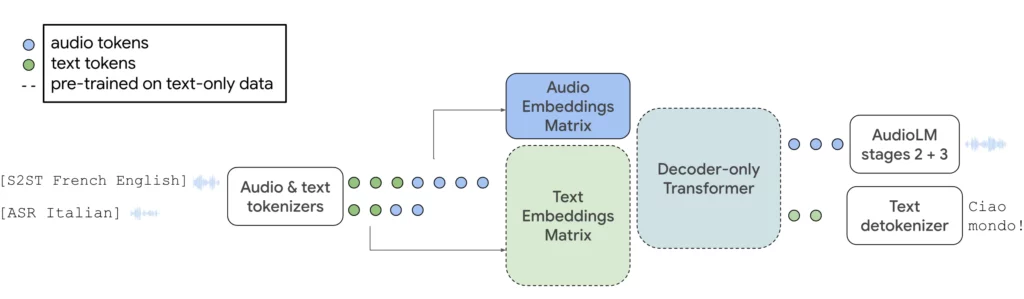
Com o AudioPaLM, o Google combina o grande modelo de linguagem PaLM-2, que foi introduzido em maio, com seu modelo de áudio generativo AudioLM em uma arquitetura multimodal central. O sistema pode processar e gerar texto e fala, e pode ser usado para reconhecimento de fala ou para gerar traduções com vozes originais.
Babelfish se aproxima
A última característica é especialmente notável, pois permite que uma pessoa fale em vários idiomas simultaneamente, como mostra a seguinte demonstração.
A condicionamento para a voz original requer apenas uma amostra de três segundos, fornecida como um áudio e um token de SoundStream. Se o arquivo de áudio for mais curto, ele será repetido até alcançar os três segundos.
Ao integrar o AudioLM, o AudioPaLM pode produzir áudio de alta qualidade com consistência a longo prazo. Isso inclui a capacidade de gerar continuações de fala semanticamente plausíveis, preservando a identidade e a prosódia do locutor para falantes não vistos durante o treinamento.
O modelo também pode realizar traduções de fala para texto sem treinamento prévio em muitos idiomas, incluindo combinações de fala não encontradas durante o treinamento. Essa capacidade pode ser importante para aplicações do mundo real, como comunicação multilíngue em tempo real.
O AudioPaLM também pode preservar informações paralinguísticas, como a identidade do locutor e a entonação, que frequentemente são perdidas em sistemas tradicionais de tradução de fala para texto. O sistema tem a expectativa de superar as soluções existentes em termos de qualidade de fala, com base em avaliação automática e humana.
Além da geração de fala, o AudioPaLM também pode gerar transcrições, seja no idioma original ou diretamente como uma tradução, ou gerar fala no idioma de origem. O AudioPaLM obteve os melhores resultados em benchmarks de tradução de fala e demonstrou desempenho competitivo em tarefas de reconhecimento de fala.
De assistentes de voz a multilinguismo automatizado
As aplicações potenciais são muitas: assistentes de voz multilíngues, serviços de transcrição automatizada e qualquer outro sistema que precise entender ou gerar linguagem humana escrita ou falada.
O Google poderia encontrar casos de uso para vídeos multilíngues gerados por IA, especialmente no YouTube: por exemplo, poderia ajudar a criar legendas multilíngues ou dublar vídeos em vários idiomas sem perder a voz do locutor original.
Os pesquisadores apontam várias áreas para pesquisas futuras, incluindo a compreensão das propriedades ótimas dos tokens de áudio e como medi-los e otimizá-los. Eles também enfatizam a necessidade de referências e métricas estabelecidas para tarefas de áudio generativo, o que ajudaria a acelerar ainda mais a pesquisa nessa área.
Mais informações e demonstrações estão disponíveis na página do projeto no GitHub.
