
Le Vision-Robotics Bridge (VRB) apprend les possibilités offertes par les environnements afin d’accélérer l’apprentissage des robots.
Plusieurs projets de recherche étudient comment les robots peuvent apprendre à partir de vidéos, car il n’existe pas suffisamment de données d’entraînement pour les robots – l’une des raisons pour lesquelles l’OpenAI, par exemple, a interrompu ses propres recherches sur la robotique.
Pour obtenir des données de formation complètes pour les robots, il faudrait que de nombreux robots effectuent des actions dans le monde réel, mais ils devraient être formés au préalable – un problème de cause à effet. La formation par le biais de vidéos est considérée comme une solution possible, car les modèles d’IA pourraient apprendre comment les humains interagissent avec l’environnement à partir de données vidéo, puis transférer ces compétences aux robots.
Le pont Vision-Robotique développe un modèle d’affordances pour les robots
Le terme « affordances », inventé par le psychologue américain James J. Gibson, fait référence au fait que les êtres vivants ne perçoivent pas les objets et les caractéristiques de leur environnement en fonction de leurs qualités, mais plutôt comme une offre à l’individu. Par exemple, les êtres vivants ne perçoivent pas une rivière simplement comme de l’eau en mouvement, mais comme une occasion de boire.
L’équipe de l’université Carnegie Mellon et de Meta AI s’inspire de ce concept et définit la possibilité dans le contexte de la robotique comme la somme du point de contact et des trajectoires post-contact. Le modèle d’IA apprend à partir de vidéos à identifier des objets avec des actions possibles, ainsi que des modèles de mouvement possibles après avoir saisi un objet.
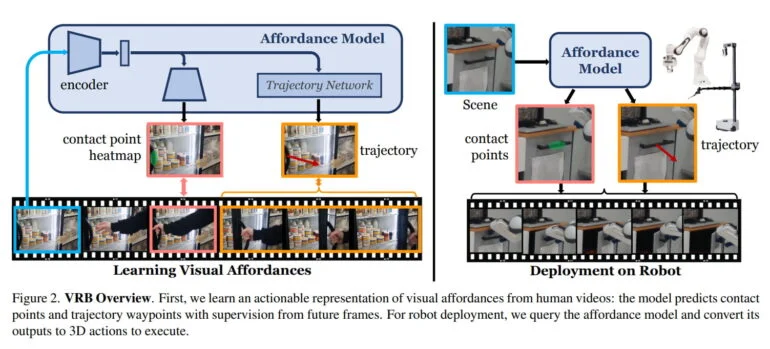
Par exemple, il apprend qu’un réfrigérateur s’ouvre en tirant sur la poignée et dans quelle direction une personne le tire. Dans le cas d’un tiroir, il reconnaît la poignée et apprend le seul sens de mouvement correct pour l’ouvrir.
La VRB a fait ses preuves au cours de 200 heures d’essais en conditions réelles.
En robotique, la VRB vise à fournir à un robot une perception contextualisée pour l’aider à apprendre ses tâches plus rapidement. L’équipe démontre que VRB est compatible avec quatre paradigmes d’apprentissage différents et applique VRB dans quatre environnements réels, sur plus de dix tâches différentes, en utilisant deux plateformes robotiques différentes.
Au cours d’expériences approfondies qui ont duré plus de 200 heures, l’équipe a démontré que la VRB est de loin supérieure aux approches précédentes. À l’avenir, les chercheurs prévoient d’appliquer leur méthode à des tâches plus complexes et à plusieurs étapes, d’intégrer des concepts physiques tels que la force et les informations tactiles, et d’étudier les représentations visuelles apprises par la VRB.
De plus amples informations sont disponibles sur la page du projet VRB. Le code et l’ensemble des données devraient également y être bientôt disponibles.
