
MosaicML a lancé le meilleur modèle de langage open source à ce jour, autorisé pour un usage commercial. L’une des variantes peut même gérer des livres entiers.
Le MPT-7B de MosaicML est un modèle de langage de grande envergure avec près de 7 milliards de paramètres, que l’équipe a formé sur son propre ensemble de données de près d’un billion de tokens.
MosaicML a suivi le régime d’entraînement du modèle LLaMA de Meta. La formation a coûté près de 200 000 dollars et a duré 9,5 jours en utilisant la plateforme MosaicML.
MosaicML MPT-7B est le meilleur modèle open source à ce jour.
Selon MosaicML, le MPT-7B correspond aux performances du modèle LLaMA de Meta avec 7 milliards de paramètres, devenant ainsi le premier modèle open source à atteindre ce niveau, devant l’OpenLLaMA.
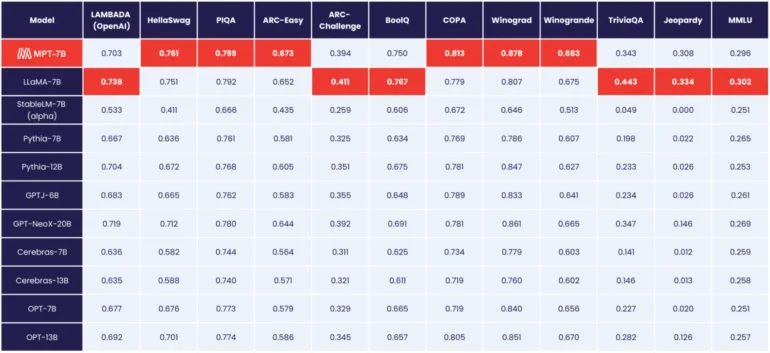
Contrairement aux modèles de Meta, cependant, le MPT-7B est sous licence pour un usage commercial.
En plus du modèle « MPT-7B Base », MosaicML propose également trois variantes : MPT-7B-StoryWriter-65k+, MPT-7B-Instruct et MPT-7B-Chat.
MosaicML lance un modèle de langage avec un contexte de 65 000 jetons
Le MPT-7B-Instruct est un modèle conçu pour suivre des instructions, tandis que le modèle Chat est une variante de chatbot dans le style Alpaca ou Vicuna.
Avec le MPT-7B-StoryWriter-65k+, MosaicML propose également un modèle capable de lire et d’écrire des histoires avec de très longs contextes. À cette fin, le MPT-7B a été ajusté avec une longueur de contexte de 65 000 jetons en utilisant un sous-ensemble de l’ensemble de données books3. La variante GPT-4 la plus importante d’OpenAI peut gérer 32 000 jetons.
Selon MosaicML, le modèle peut évoluer au-delà de 65 000 jetons avec quelques optimisations, et l’équipe a même démontré une capacité allant jusqu’à 84 000 jetons sur un seul nœud en utilisant les GPU Nvidia A100-80GB. Mais même avec 65 000 jetons, il était possible de lire des romans entiers et d’écrire un épilogue.

Tous les modèles MPT-7B sont disponibles sur GitHub.
