
D’une certaine manière, les humains et les grands modèles de langage semblent présenter des comportements similaires : ils répondent particulièrement bien aux informations au début ou à la fin d’un contenu. Les informations au milieu ont tendance à être perdues.
Des chercheurs de l’Université de Stanford, de l’Université de Californie à Berkeley et de Samaya AI ont découvert un effet dans les LLMs (grands modèles de langage) qui rappelle l’effet de primauté/récence connu chez les humains. Cela signifie que les gens ont tendance à se souvenir du contenu au début et à la fin d’une déclaration. Le contenu au milieu est plus susceptible d’être ignoré.
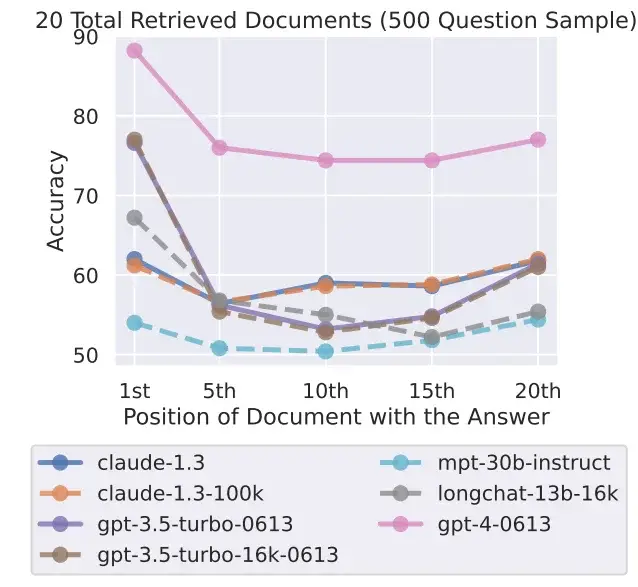
Selon l’étude, un effet similaire se produit avec les grands modèles de langage : lorsqu’ils sont sollicités pour récupérer des informations à partir d’une entrée, les modèles ont de meilleures performances lorsque les informations se trouvent au début ou à la fin de l’entrée.
Cependant, lorsque l’information pertinente se trouve au milieu de l’entrée, les performances diminuent significativement. Cette baisse de performance est particulièrement prononcée lorsque le modèle est sollicité pour répondre à une question qui nécessite d’extraire des informations de plusieurs documents – l’équivalent d’un étudiant devant identifier des informations pertinentes dans plusieurs livres pour répondre à une question lors d’un examen.
Plus la quantité d’entrée que le modèle doit traiter simultanément est grande, plus ses performances tendent à être mauvaises. Cela peut poser problème dans des scénarios du monde réel où il est important de traiter de grandes quantités d’informations de manière simultanée et équitable.
Les résultats suggèrent également qu’il y a une limite à la manière dont les grands modèles de langage peuvent utiliser efficacement des informations supplémentaires, et que les « méga-prompts » avec des instructions particulièrement détaillées feront probablement plus de mal que de bien.
À quel point les LLMs avec de grandes fenêtres de contexte sont-ils utiles ?
Le phénomène de « perte au milieu » se produit également avec des modèles spécifiquement conçus pour traiter de nombreux contextes, tels que le GPT-4 32K ou le Claude avec sa fenêtre de contexte de 100 000 tokens.
Les chercheurs ont testé sept modèles de langage ouverts et fermés, y compris le nouveau GPT-3.5 16K et le Claude 1.3 avec 100K. Tous les modèles ont présenté une courbe en forme de U plus ou moins prononcée, selon le test, avec de meilleures performances dans les tâches où la solution se trouve au début ou à la fin du texte.

Isso soulève la question de l’utilité des modèles avec une grande fenêtre de contexte lorsque de meilleurs résultats peuvent être obtenus en traitant le contexte en morceaux plus petits. Le modèle actuel leader, le GPT-4, montre également cet effet, mais à un niveau de performance globalement plus élevé.
L’équipe de recherche reconnaît qu’on ne comprend pas encore complètement comment les modèles traitent le langage. Cette compréhension doit être améliorée grâce à de nouvelles méthodes d’évaluation, et de nouvelles architectures pourraient également être nécessaires.
Les chercheurs affirment également qu’il est nécessaire d’étudier comment la conception des prompts affecte les performances du modèle. Rendre les systèmes d’IA plus conscients de la tâche en question dans un prompt pourrait améliorer leur capacité à extraire des informations pertinentes.
