
Un prompt complexe de l’entreprise de marketing cloud Salesforce vise à améliorer la qualité des résumés d’articles en utilisant GPT-4.
Le prompt ‘Chaîne de Densité’ demande d’abord à GPT-4 de créer un premier brouillon d’un résumé avec le moins d’éléments possible. Aux étapes suivantes, le prompt demande à GPT-4 de réviser ce résumé et d’ajouter plus de détails.
Tout comme avec le prompt ‘Chaîne de Pensée’, le modèle utilise la première sortie générée comme modèle pour la génération suivante. Plus le modèle passe par ce processus, plus la densité d’informations dans le résumé sera élevée pour la même longueur de caractères.
« Les résumés générés par le CoD sont plus abstraits, montrent plus de fusion et ont moins de biais de plomb que les résumés GPT-4 générés par un prompt classique », écrit l’équipe.
Article: {{article}
You will generate increasingly concise entity-dense summaries of the above article. Repeat the following 2 steps 5 times.
Step 1: Identify 1-3 informative entities (delimited) from the article which are missing from the previously generated summary.
Step 2: Write a new denser summary of identical length which covers every entity and detail from the previous summary plus the missing entities.
A missing entity is
- Relevant: to the main stories.
- Specific: descriptive yet concise (5 words or fewer).
- Novel: not in the previous summary.
- Faithful: present in the article.
- Anywhere: located in the article.
Guidelines:
- The first summary should be long (4-5 sentences, ~80 words), yet highly non-specific, containing little information beyond the entities marked as missing. Use overly verbose language and fillers (e.g., "this article discusses") to reach ~80 words.
- Make every word count. Rewrite the previous summary to improve flow and make space for additional entities.
- Make space with fusion, compression, and removal of uninformative phrases like "the article discusses".
- The summaries should become highly dense and concise, yet self-contained, e.g., easily understood without the article.
- Missing entities can appear anywhere in the new summary.
- Never drop entities from the previous summary. If space cannot be made, add fewer new entities.
Remember: Use the exact same number of words for each summary.
Answer in JSON. The JSON should be a list (length 5) of dictionaries whose keys are "missing_entities" and "denser_summary".
Image: Salesforce
La complexité des résumés
L’équipe de recherche a testé le prompt sur 100 articles de presse de CNN et de DailyMail. Les examinateurs humains, en l’occurrence quatre des auteurs de l’article, ont classé les résumés les mieux notés après environ trois passages.
En moyenne, GPT-4 a mieux classé les résumés en termes d’informations, de qualité, de cohérence, d’attribution et de ‘global’ après deux passages. Il est dit que la méthode CoD est supérieure à un prompt plus simple testé (‘Écrivez un résumé TRÈS court de l’article. Ne dépassez pas 70 mots.’).
« Nous avons constaté qu’un degré de densification est préférable, cependant, lorsque les résumés contiennent de nombreuses entités par jeton, il est très difficile de maintenir la lisibilité et la cohérence », écrit l’équipe.
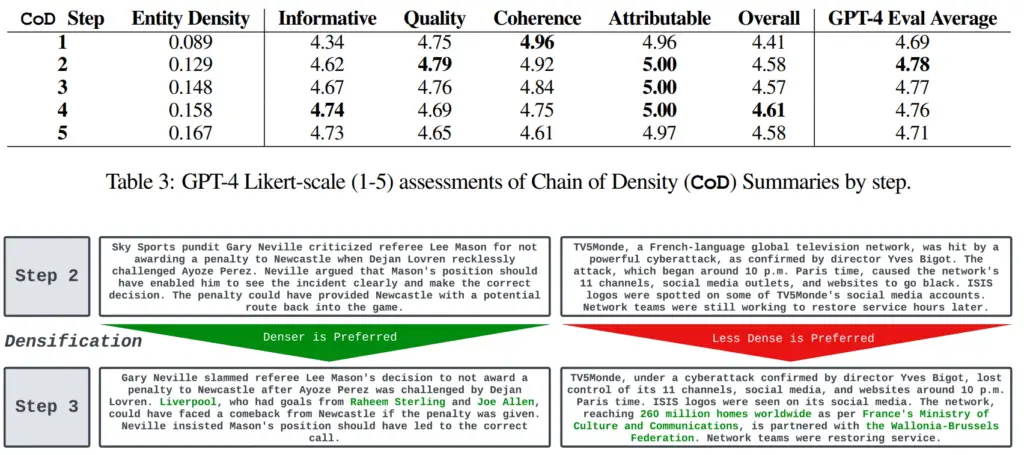
Image: Salesforce
En général, la première et la dernière étape obtiennent les scores les plus bas, tandis que les trois résumés du milieu sont proches. Il est logique que la première note de résumé soit plus basse, étant donné que le prompt demande au modèle d’écrire d’abord un résumé superficiel.
Le fait que les résultats soient si proches montre également à quel point il est difficile d’évaluer les textes au-dessus d’un certain niveau. Cela complique à son tour la mesure de l’impact de l’ingénierie immédiate.
L’équipe de recherche publie un ensemble de données comprenant 500 résumés CoD annotés et 5000 non annotés à côté du prompt.
