
Avec AudioPaLM, Google ajoute des capacités audio à son grand modèle linguistique PaLM-2. Cela permet de réaliser des traductions orales avec la voix du locuteur d’origine.
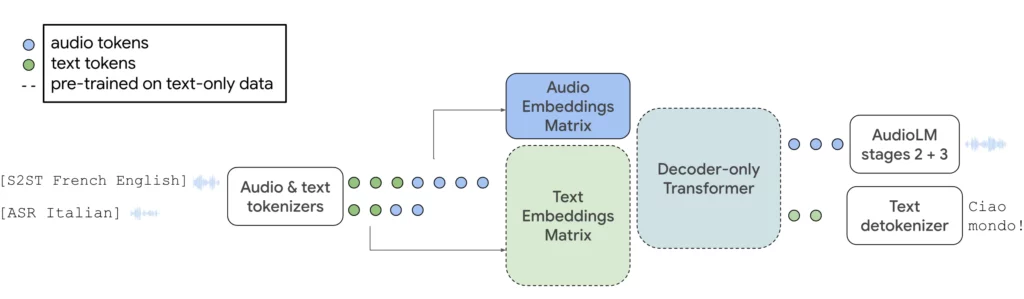
Avec AudioPaLM, Google combine le grand modèle linguistique PaLM-2, présenté en mai, avec son modèle audio génératif AudioLM dans une architecture multimodale centrale. Le système peut traiter et générer du texte et de la parole, et peut être utilisé pour la reconnaissance vocale ou pour générer des traductions avec des voix originales.
Babelfish se rapproche
La dernière caractéristique est particulièrement remarquable, car elle permet à une personne de parler dans plusieurs langues simultanément, comme le montre la démo suivante.
Le conditionnement de la voix originale ne nécessite qu’un échantillon de trois secondes, fourni sous la forme d’un fichier audio et d’un jeton SoundStream. Si le fichier audio est plus court, il sera répété jusqu’à ce qu’il atteigne trois secondes.
En intégrant AudioLM, AudioPaLM peut produire un son de haute qualité avec une cohérence à long terme. Il est notamment capable de générer des suites de discours sémantiquement plausibles, en préservant l’identité du locuteur et la prosodie pour les locuteurs qui n’ont pas été vus pendant la formation.
Le modèle peut également effectuer des traductions parole-texte sans formation préalable dans de nombreuses langues, y compris dans des combinaisons vocales non rencontrées lors de la formation. Cette capacité peut s’avérer importante pour des applications réelles, telles que la communication multilingue en temps réel.
AudioPaLM peut également préserver les informations paralinguistiques, telles que l’identité du locuteur et l’intonation, qui sont souvent perdues dans les systèmes traditionnels de traduction de la parole au texte. Le système devrait surpasser les solutions existantes en termes de qualité vocale, selon une évaluation automatique et humaine.
Outre la génération de la parole, AudioPaLM peut également générer des transcriptions, soit dans la langue d’origine, soit directement en tant que traduction, ou encore générer de la parole dans la langue source. AudioPaLM a obtenu les meilleurs résultats dans les tests de traduction de la parole et a démontré des performances compétitives dans les tâches de reconnaissance de la parole.
Des assistants vocaux au multilinguisme automatisé
Les applications potentielles sont nombreuses : assistants vocaux multilingues, services de transcription automatique et tout autre système qui doit comprendre ou générer du langage humain écrit ou parlé.
Google pourrait trouver des cas d’utilisation pour les vidéos multilingues générées par l’IA, notamment sur YouTube : par exemple, elle pourrait aider à créer des sous-titres multilingues ou à doubler des vidéos dans plusieurs langues sans perdre la voix de l’orateur original.
Les chercheurs soulignent plusieurs domaines de recherche future, notamment la compréhension des propriétés optimales des jetons audio et la manière de les mesurer et de les optimiser. Ils soulignent également la nécessité d’établir des critères de référence et des mesures pour les tâches audio génératives, ce qui permettrait d’accélérer la recherche dans ce domaine.
De plus amples informations et des démonstrations sont disponibles sur la page GitHub du projet.
