
FinGPT est un cadre d’IA conçu pour faciliter l’accès aux modèles linguistiques optimisés pour les tâches financières. Il s’agit d’un logiciel libre qui peut être utilisé à des fins commerciales.
Avec FinGPT, l’équipe de recherche de l’université de Columbia et de l’université de New York (Shanghai) vise à démocratiser l’accès aux modèles de langage optimisés pour les marchés financiers.
Les modèles propriétaires, tels que BloombergGPT, bénéficieraient d’un accès à des données financières uniques, affirment les chercheurs. En outre, ils affirment que BloombergGPT est trop cher, estimé à cinq millions de dollars américains pour la formation, et trop rigide.
Au lieu de cela, FinGPT utilise des modèles linguistiques préformés et un réglage fin à l’aide de la méthode LoRA (Low-Rank Efficient Adaptation). Selon l’équipe, la méthode LoRA peut réduire le nombre de paramètres entraînables de 6,17 milliards à seulement 3,67 millions. Le processus de réglage fin est ainsi beaucoup plus rapide et moins gourmand en ressources informatiques, tout en permettant au modèle de comprendre et de produire des textes financiers de manière efficace.
Se concentrer sur des flux de données de haute qualité
Les chercheurs affirment que le succès d’un modèle de langage financier dépend à la fois des capacités du modèle de langage et de la qualité des données. Ils considèrent FinGPT comme une réponse directe à BloombergGPT et mettent donc fortement l’accent sur la qualité et la préparation des données.
L’équipe a d’abord développé un pipeline automatisé de données financières sélectionnées et de haute qualité. Elle utilise des sources établies telles que Yahoo Finance et Bloomberg, ainsi que du contenu provenant de plateformes telles que Twitter, Reddit et les dépôts de la SEC (US Securities and Exchange Commission). Ils tirent également des informations d’indicateurs de tendances tels que Google Trends et d’ensembles de données consolidées tels que AShare et Stocknet.
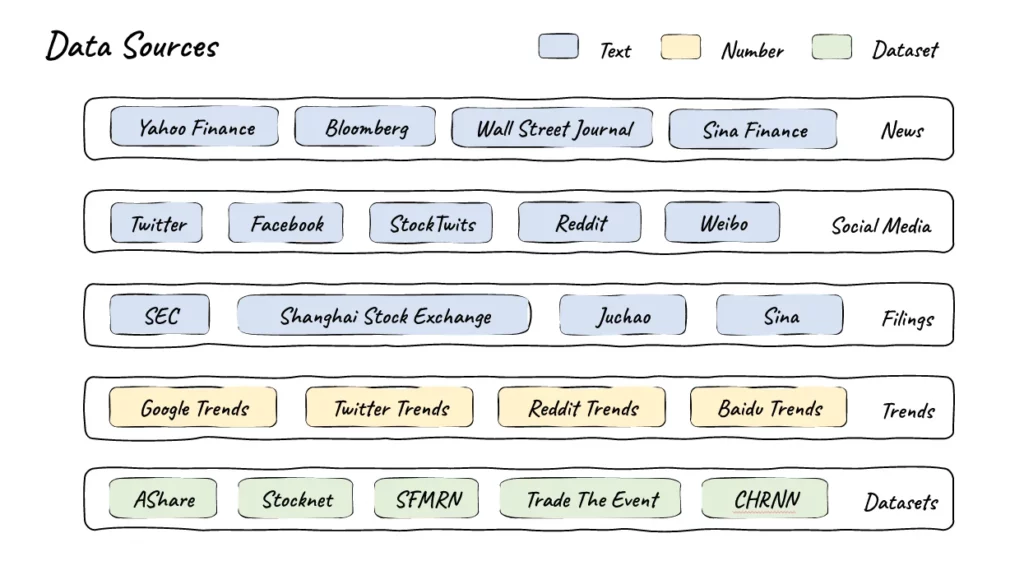
Selon l’équipe, ces données sont soumises à un processus complet de nettoyage et de formatage afin d’en garantir la qualité et la facilité d’utilisation.
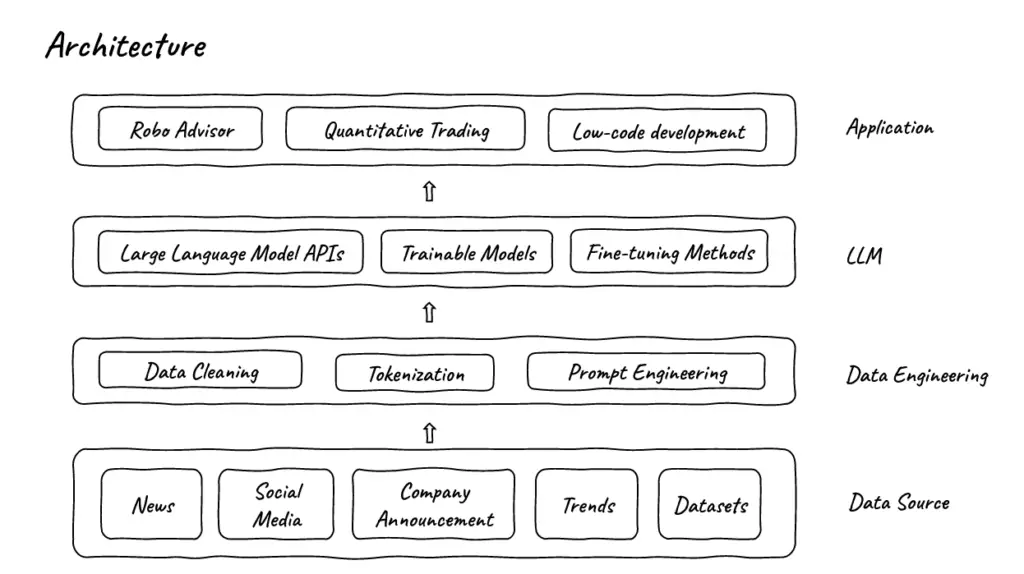
Les données sont ensuite traitées à l’aide de modèles linguistiques dans le cadre de FinGPT. Selon l’application, il est possible d’utiliser des LLM (modèles d’apprentissage du langage) provenant d’entreprises renommées, ou d’enrichir des modèles entraînables ou ajustables avec des données personnalisées. Le réglage fin étant plus rapide que l’entraînement complet d’un modèle, FinGPT est considéré comme plus actuel et plus dynamique que BloombergGPT.
Retour d’information humain automatisé par le biais d’une déviation
La mise au point d’un modèle nécessite généralement une grande quantité de données étiquetées de haute qualité. Par données étiquetées, on entend des données contenant des informations supplémentaires à partir desquelles le modèle peut apprendre, par exemple si une nouvelle est considérée comme bonne ou mauvaise. L’obtention de ces données peut s’avérer difficile et coûteuse, en particulier dans des domaines spécialisés tels que la finance.
C’est pourquoi l’équipe de FinGPT a trouvé une solution élégante : au lieu d’étiqueter manuellement les données, elle utilise les réactions du marché boursier aux nouvelles comme étiquettes. Par exemple, si le cours de l’action augmente après une nouvelle, celle-ci peut être qualifiée de « positive ».
Les chercheurs ont fixé des seuils pour les trois sentiments : positif, négatif et neutre. Lors de l’ajustement du modèle, il est demandé de sélectionner l’un des trois sentiments – positif, négatif ou neutre – comme étiquette de l’information.
Suivant l’approche RLHF (Reinforcement Learning with Human Feedback) de l’OpenAI, les chercheurs ont appelé leur principe RLSP (Reinforcement Learning on Stock Prices), qui peut être considéré comme une forme indirecte de feedback humain. Le système devrait apprendre de la « sagesse du marché » pour mieux comprendre et prévoir les marchés financiers.
Un cadre open-source pour l’IA dans le secteur financier
L’équipe cite des applications potentielles du cadre FinGPT telles que le conseil robotisé, le trading quantitatif, l’optimisation de portefeuille basée sur différents facteurs, l’analyse des sentiments sur les marchés financiers, la gestion des risques, la détection des fraudes, l’évaluation du crédit, la prédiction de l’insolvabilité ou d’éventuelles acquisitions, l’analyse des profils ESG basée sur les rapports publics et les actualités, le développement de code bas et l’éducation financière.
Les chercheurs mettent FinGPT à disposition en tant que source ouverte sous la licence MIT sur Github. L’utilisation commerciale est autorisée. Les développeurs ne garantissent pas et n’assument pas la responsabilité des décisions financières basées sur le modèle. Avec le contenu du décodeur.
