
Le modèle linguistique open source FalconLM offre de meilleures performances que le modèle LLaMA de Meta et peut également être utilisé à des fins commerciales. Toutefois, l’utilisation commerciale est soumise au paiement de redevances si le chiffre d’affaires dépasse 1 million d’USD.
FalconLM est développé par le Technology Innovation Institute (TII) à Abu Dhabi, aux Émirats arabes unis. L’organisation affirme que FalconLM est le modèle linguistique open source le plus puissant à ce jour, bien que sa plus grande variante, avec 40 milliards de paramètres, soit nettement plus petite que LLaMA de Meta, qui compte 65 milliards de paramètres.
Dans le Hugging Face OpenLLM Leaderboard, qui résume les résultats de divers benchmarks, les deux plus grands modèles FalconLM, dont l’un a été affiné avec des instructions, occupent actuellement les deux premières places avec une marge significative. TII propose également un modèle à 7 milliards de paramètres.
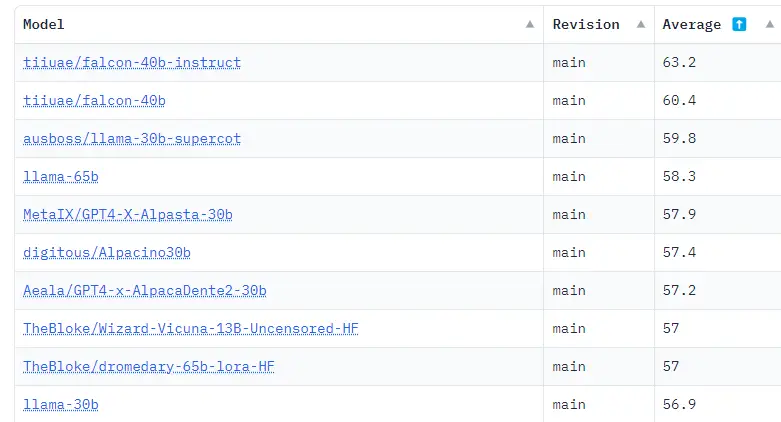
FalconLM s’entraîne plus efficacement que GPT-3
Selon l’équipe de développement, un aspect important de l’avantage concurrentiel de FalconLM est la sélection des données pour l’entraînement. Les modèles linguistiques sont sensibles à la qualité des données lors de la formation.
L’équipe de recherche a mis au point un processus permettant d’extraire des données de haute qualité du célèbre ensemble de données Common Crawl et de supprimer les doublons. Malgré ce nettoyage approfondi, il restait cinq trillions de fragments de texte (tokens) – suffisamment pour entraîner de puissants modèles de langage. La fenêtre contextuelle est de 2048 tokens, juste en dessous du niveau ChatGPT.
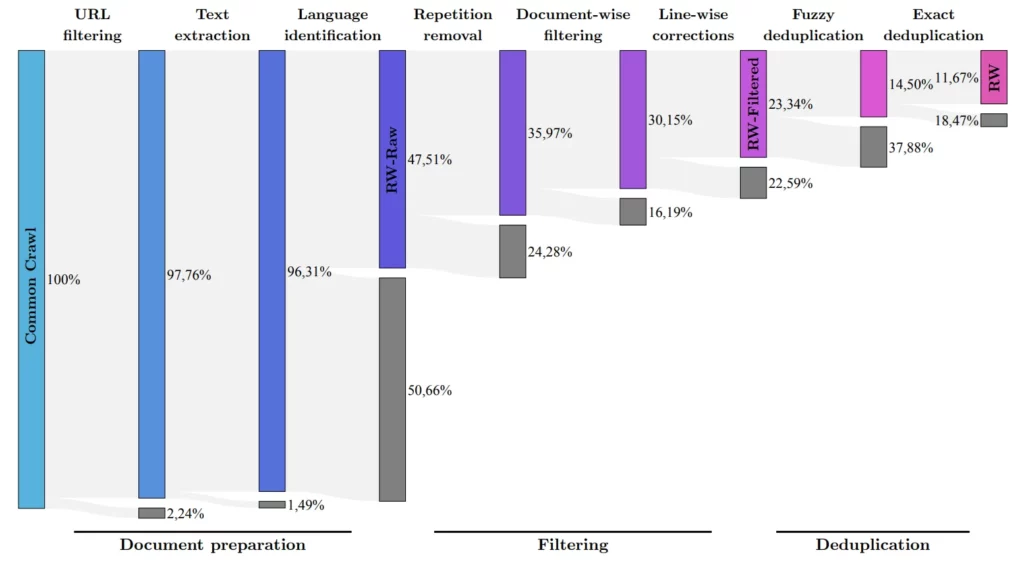
Le FalconLM avec 40 milliards de paramètres a été entraîné avec un trillion de tokens, tandis que le modèle avec 7 milliards de paramètres a été entraîné avec 1,5 trillion de tokens. Les données de l’ensemble RefinedWeb ont été enrichies de « quelques » ensembles de données sélectionnés dans des articles scientifiques et des discussions sur les médias sociaux. La version la plus performante, celle du chatbot, a été affinée à l’aide de l’ensemble de données Baize.
TII mentionne également une architecture optimisée pour la performance et l’efficacité, mais ne fournit pas de détails. Le document n’est pas encore disponible.
Selon l’équipe, l’architecture optimisée, combinée à un ensemble de données de haute qualité, a permis à FalconLM de ne nécessiter que 75 % de l’effort de calcul de GPT-3 pendant l’entraînement, tout en surpassant de manière significative l’ancien modèle OpenAI. Les coûts d’inférence seraient inférieurs d’un cinquième à ceux de GPT-3.
Disponible en tant que source ouverte, mais l’utilisation commerciale peut être coûteuse
Les cas d’utilisation de l’IIT pour FalconLM comprennent la génération de texte, la résolution de problèmes complexes, l’utilisation du modèle comme chatbot personnel ou dans des domaines commerciaux tels que le service à la clientèle ou la traduction.
Dans les applications commerciales, cependant, TII souhaite bénéficier d’un million de dollars de revenus attribuables au modèle linguistique : dix pour cent des revenus sont dus à titre de redevances. Toute personne intéressée par une utilisation commerciale doit contacter le service commercial de TII. Pour un usage personnel et la recherche, FalconLM est gratuit.
Toutes les versions des modèles FalconLM peuvent être téléchargées gratuitement sur Huggingface. Outre les modèles, l’équipe publie également une partie de l’ensemble de données « RefinedWeb », qui comprend 600 milliards de jetons de texte, en tant que source ouverte sous une licence Apache 2.0. L’ensemble de données est également prêt pour une extension multimodale, puisque les exemples incluent déjà des liens et des textes alternatifs pour les images.
