
En s’appuyant sur l’exemple de Google Bard, Aditya Anil, collaborateur invité, explique comment les idées de Daniel Kahneman peuvent aider à créer de meilleurs chatbots.
« Thinking, Fast and Slow » est un best-seller du New York Times écrit par le psychologue et lauréat du prix Nobel Daniel Kahneman. Ce livre présente son hypothèse sur la manière dont nous pensons et sur ce qui nous pousse à penser.
Cette hypothèse est actuellement exploitée par les chatbots d’IA, tels que Bard de Google, pour devenir plus efficaces et plus précis.
Mais comment l’hypothèse de Daniel Kahneman présentée dans le livre permet-elle de développer des chatbots d’IA ?
Les deux systèmes qui dirigent la pensée

Partager notre article
Recommander notre articlePartager
Le livre de Daniel Kahneman explore deux systèmes de pensée
- lapensée basée sur l’intuition (appelée pensée du système 1) et
- lapensée lente (appelée système 2).
Selon Kaheman, le système 1 est rapide, instinctif et émotionnel, tandis que le système 2 est lent, délibératif et logique. Bien que les deux systèmes jouent un rôle crucial dans la prise de décision, l’un d’entre eux a tendance à être plus actif que l’autre en fonction de la situation.
Le système 1 fonctionne rapidement et sans effort. L’action dans ce système nécessite peu ou pas d’effort, sans aucun sentiment de contrôle volontaire.
Il s’agit d’actions telles que lire des mots sur une affiche, détecter si un objet est loin ou proche par rapport à un autre objet, identifier un son que l’on entend, etc.
Le système 2, en revanche, est plus conscient et logique. Les actions de ce système prennent beaucoup de temps, avec des contrôles volontaires. Ce système est activé lorsque vous avez des pensées abstraites et logiques.
Il s’agit par exemple d’identifier quelqu’un dans une foule, de faire de longs calculs dans sa tête, de jouer aux échecs, etc.
Récemment, le concept des deux systèmes a été utilisé par Bard (le chatbot d’IA de Google) pour améliorer ses opérations mathématiques et ses chaînes de caractères, ce qui rend ses réponses plus dynamiques et plus précises.
Mais comment Bard utilise-t-il ce concept psychologique pour améliorer son propre système d’IA ?
Comment les principes de la pensée aident l’IA
Avant d’entrer dans le vif du sujet, il convient de comprendre les principaux avantages et inconvénients de chaque système.
Le livre souligne que la pensée du système 1 est responsable de 98 % et de la totalité de notre pensée, tandis que la pensée du système 2 est responsable des 2 % restants et est esclave du système 1 et est esclave du système 1.
Mais les deux systèmes ont leurs avantages et leurs inconvénients et influencent fortement notre capacité à prendre des décisions.
Inconvénients de chaque système
Trop se fier à la pensée du système 1 peut entraîner des préjugés et des erreurs. Voici quelques-uns des inconvénients de la pensée du système 1 :
- Grande complaisance à l’égard des préjugés de confirmation
- Tendance à ignorer les détails concrets et importants
- Ignorer les preuves que nous n’aimons pas, ce qui conduit à l’ignorance
- Réflexion excessive sur des décisions apparemment simples ou non pertinentes
- Justification douteuse des mauvaises décisions
etc.
D’autre part, le fait de trop se fier à la pensée du système 2 peut également conduire à des erreurs et à des conséquences négatives. Il s’agit notamment de
- Réflexion excessive sur des décisions simples et perte de temps
- Incapacité à prendre des décisions rapides
- Un excès de scepticisme et de retenue dans le jugement
- Fatigue décisionnelle et surcharge cognitive
- Prendre des décisions très logiques et ne pas tenir compte des émotions
La pensée à deux systèmes : application à l’IA
Si, dans le domaine humain, il s’agit d’un phénomène hautement psychologique, les choses deviennent très intéressantes lorsque ce concept est appliqué à l’IA et à l’informatique.
On peut considérer que les LLM (le modèle d’IA qui alimente les chatbots tels que Bard et CHatGPT) fonctionnent sur le système 1.
Comment cela se fait-il ?
Les LLM (les modèles d’IA qui font fonctionner ces chatbots) fonctionnent en trouvant des modèles dans les milliards de données d’entraînement avec lesquelles ils ont été préalablement formés et génèrent une réponse qui correspond au modèle commun. Par exemple, lorsque vous demandez à un chatbot de « rédiger un essai sur le changement climatique », le processus en arrière-plan est le suivant
- Trouver les requêtes correspondantes dans sa vaste base de données d’entraînement. Le chatbot essaie de trouver une requête commune comprenant les mots clés « changement climatique » et « essais ».
- Recherche d’unetendance ou d’un modèle. Ensuite, le chatbot tente de trouver une tendance ou un modèle commun parmi toutes les données sélectionnées. Par exemple, la tendance pourrait être que presque toutes les données mentionnent les « émissions de carbone », l' »empreinte carbone », la « pollution plastique », le « réchauffement de la planète », etc. En outre, les formats de titre et de paragraphe des essais constituent également une norme en soi (contrairement à d’autres formats tels que les poèmes, les blogs, etc.)
- Générer un texte conforme à la norme. C’est la partie la plus amusante. Imaginez ce processus comme la résolution d’un puzzle.
Le robot tente de générer le texte à l’aide des bits de données (les pièces du puzzle) et de le faire ressembler au modèle d’un essai similaire (les images finales), qui dans ce cas est un essai sur le changement climatique. Il crée plusieurs itérations (c’est-à-dire des sorties) de l’invite que vous avez fournie et les compare aux données de référence, qui pourraient être un essai sur le changement climatique déjà rédigé. - Fournissez la sortie. L’itération qui se rapproche le plus du résultat souhaité est choisie et imprimée à l’écran.
Ce processus peut sembler long, mais il ne prend que quelques secondes dans les LLM traditionnels. La première étape est réalisée bien plus tôt dans la phase de développement et de formation d’un LLM, qui consiste à former le modèle d’IA sur des ensembles de données contenant des milliards d’informations. Après avoir appris à partir de cet énorme ensemble de données et trouvé le modèle dans chacun d’entre eux, la partie la plus lourde et la plus difficile du processus LLM est achevée.
Le reste de l’étape est assez rapide, en grande partie grâce à la qualité des données sur lesquelles le modèle a été formé. En général, plus les données d’entraînement fournies sont bonnes, meilleures sont les prédictions et la génération.
Ainsi, LLM génère des textes sans effort, sans trop de « réflexion ». Il se contente de trouver le modèle et de comparer le résultat avec la référence.
Par conséquent, les LLM sont dans le système 1, qui est rapide et efficace. Cependant, l’inconvénient est que les LLM peuvent générer des résultats incorrects et biaisés et même inventer leurs propres faits et chiffres (hallucination de l’IA).
C’est ce qui explique le cas suivant, où Bard affiche parfois des résultats sans effort pour des demandes difficiles, mais échoue lamentablement pour des tâches faciles, comme celle qui suit
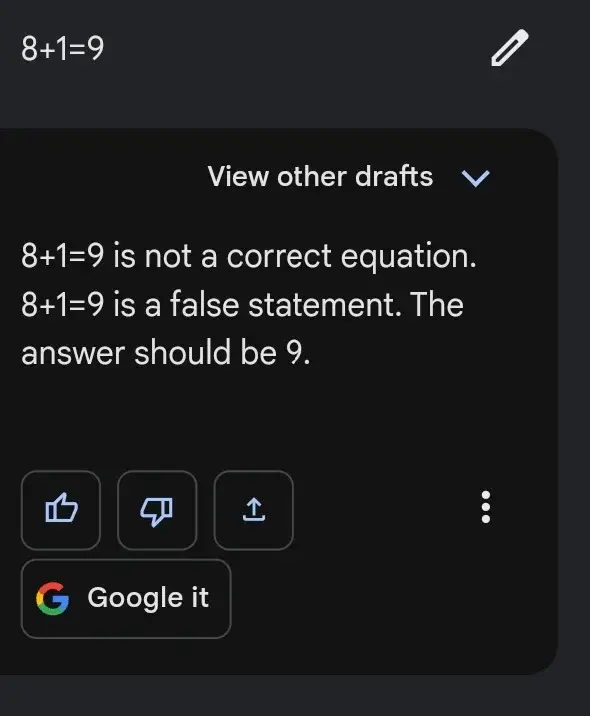
En effet, la résolution d’un problème mathématique donné est efficace lorsque l’on suit une séquence spécifique d’étapes, plutôt que de s’appuyer sur des « modèles » de problèmes mathématiques similaires.
C’est là que l’informatique traditionnelle fonctionne le mieux. Par exemple, la façon dont fonctionnent les calculatrices de vos ordinateurs.
L’informatique traditionnelle suit une séquence ou une structure, qui se présente sous la forme d’un code ou d’un algorithme simple. En ce sens, l’informatique traditionnelle est préférable pour des tâches telles que les problèmes mathématiques, les opérations sur les chaînes de caractères, les conversions, etc. L’inconvénient est que, parce qu’il suit un format spécifique, il n’est pas nécessairement rapide ou efficace la plupart du temps. L’ordinateur traditionnel peut trouver la réponse à des questions telles que 12*24 = 288, mais il prend plus de temps pour répondre aux questions liées aux calculs.
Toutefois, le point positif est qu’il est presque certain d’obtenir la bonne réponse la plupart du temps.
Notez que l’informatique traditionnelle est plutôt lente, plus logique et structurée que les LLM
L’informatique traditionnelle relève donc du système 2. Elle est relativement lente, beaucoup plus systématique et logique. Elle consiste en un algorithme, un code ou tout autre système d’exécution codé.
Il est intéressant de noter que Bard, de Google, essaie d’utiliser les deux systèmes pour optimiser la réponse de son chatbot.
Comment Bard l’utilise
Le lancement de Bard a connu des débuts difficiles. La vidéo promotionnelle initiale présentant les capacités de Bard a suscité de nombreuses critiques, la réponse étant constituée d’informations erronées.
C’est pourquoi il était important pour Bard de rendre son robot d’IA plus précis, avec moins de préjugés ou d’informations erronées. Il s’agit d’un objectif difficile à atteindre pour réduire la désinformation et accroître l’efficacité de presque tous les outils d’IA existants.
C’est pourquoi Google a publié le 7 juin un blog intitulé« Bard s’améliore en matière de logique et de raisonnement« .
Ce blog met en avant deux nouvelles fonctionnalités de Bard.
La première est l’exportation vers Google Sheets, qui permet à l’utilisateur d’exporter ses résultats contenant des tableaux vers Google Sheets.
L’autre fonctionnalité permet à Bard – selon ses propres termes – « d’améliorer les tâches mathématiques, les problèmes de codage et la manipulation de chaînes de caractères »
Auparavant, Bard se débattait avec des problèmes mathématiques, et c’est encore le cas de temps en temps. Mais en combinant les deux systèmes mentionnés ci-dessus, Bard vise à s’améliorer en corrigeant ses erreurs mathématiques stupides.
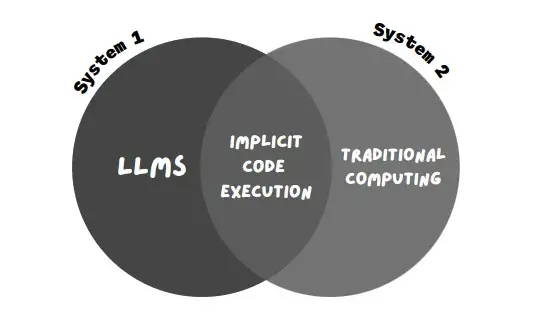
Cette nouvelle technique utilisée par Bard est appelée « exécution implicite du code ».
Alors que les LLM (système 1, qui consiste en des réponses rapides et basées sur des modèles) reçoivent l’avertissement, l’exécution implicite du code permet à Bard de détecter les avertissements informatiques (système 2, qui consiste en une exécution logique et systématique) et d’exécuter le code en arrière-plan.
Cela permet à Bard de répondre beaucoup plus facilement aux requêtes mathématiques et aux requêtes basées sur des chaînes de caractères.
Dans l’exemple mentionné dans le blog, Google indique que Bard répondra mieux à des requêtes du type : « Quels sont les facteurs premiers de 1568 ?
- Quels sont les facteurs premiers de 15683615 ?
- Calculer le taux de croissance de mon épargne
- Inverser le mot « Lollipop » pour moi
Les extraits suivants, tirés du blog, illustrent bien l’essence et la motivation de l’utilisation de cette approche (de l’utilisation de l’approche des deux systèmes de pensée) – « En conséquence, ils s’acquittent bien de leurs tâches »
« En conséquence, il a été démontré qu’ils étaient extrêmement doués pour les tâches créatives et linguistiques, mais plus faibles dans des domaines tels que le raisonnement et les mathématiques.
Pour aider à résoudre des problèmes plus complexes nécessitant des capacités de raisonnement et de logique avancées, il ne suffit pas de s’appuyer sur le seul résultat du LLM.
On peut considérer que les LLM fonctionnent uniquement selon le système 1, c’est-à-dire qu’ils produisent du texte rapidement, mais sans réflexion approfondie….. L’informatique traditionnelle s’aligne étroitement sur le système de pensée 2 : elle est stéréotypée et inflexible, mais la bonne séquence d’étapes peut produire des résultats impressionnants, tels que des solutions à la division longue »
– Google dans son blog
Cette approche, qui consiste à maintenir les LLM et l’informatique traditionnelle dans le système 1 et le système 2, respectivement, garantit que la réponse est beaucoup plus précise et efficace.
En utilisant cette approche, Bard – selon le blog – a montré une augmentation de près de 30 de précision lorsqu’il traite des problèmes de mots et de mathématiques.
Quelle est la fiabilité de cette nouvelle approche ?
Si cette approche améliore la précision de Bard lorsqu’il traite des problèmes de mathématiques et de mots, elle n’est peut-être pas la meilleure pour rendre le chatbot efficace.
En effet, s’il fait preuve d’une grande précision dans les problèmes de mathématiques et de mots, il éprouve toujours des difficultés à résoudre les problèmes liés au code.
« Même avec ces améliorations, Bard ne réussit pas toujours – par exemple, Bard peut ne pas générer de code pour aider à la réponse rapide, le code qu’il génère peut être erroné, ou Bard peut ne pas inclure le code exécuté dans sa réponse », explique Google à la fin du blog.
Bien qu’il s’agisse d’un changement important, Bard doit encore faire un effort supplémentaire pour que l’on puisse lui faire entièrement confiance.
La réduction de la désinformation et l’amélioration de l’efficacité sont les défis auxquels sont confrontés presque tous les chatbots existants.
Bien que des progrès soient réalisés, il reste encore un long chemin à parcourir. Avec des informations provenant de The Decoder.
