
InternLM est un grand modèle linguistique comportant 104 milliards de paramètres, introduit par le laboratoire national d’IA de Chine, Shanghai AI Lab, en partenariat avec la société de surveillance SenseTime.
L’université chinoise de Hong Kong, l’université Fudan et l’université Jiaotong de Shanghai ont également participé à son développement. Dans les tâches en langue chinoise, il surpasse nettement ChatGPT d’OpenAI et Anthropics Claude.
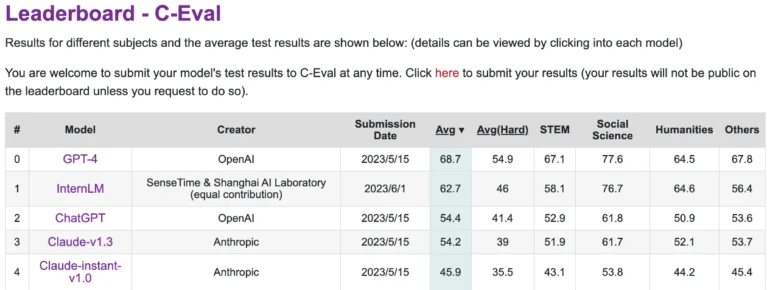
Cependant, il est à la traîne par rapport à GPT-4 sur C-Eval, une plateforme qui évalue les performances des grands modèles de langage en chinois. InternLM a été entraîné sur 1,6 trillion de tokens et, comme GPT-4, a été affiné pour répondre aux besoins humains à l’aide de RLHF et d’exemples sélectionnés. Il est basé sur une architecture de transformateur similaire à celle du GPT.
La formation était principalement basée sur des données provenant de Massive Web Text, enrichies d’encyclopédies, de livres, d’articles scientifiques et de codes. Les chercheurs ont également développé le système de formation Uniscale LLM, capable de former de manière fiable de grands modèles de langage avec plus de 200 milliards de paramètres sur 2048 GPU en utilisant un ensemble de techniques de formation parallèle.
InternLM atteint des performances équivalentes à celles de ChatGPT dans les tests de référence
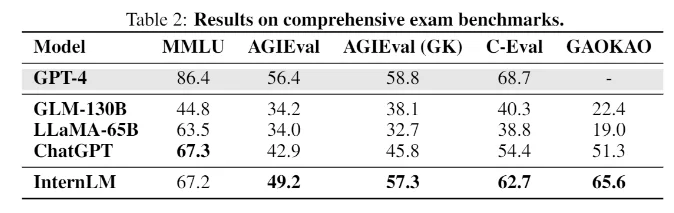
Sur les benchmarks dont les tâches simulent des examens humains, tels que MMLU, AGIEval, C-Eval et GAOKAO Bench, InternLM atteint également des performances comparables à celles de ChatGPT. Cependant, il n’atteint pas le niveau de GPT-4, ce que les chercheurs attribuent à la petite fenêtre contextuelle de seulement 2000 tokens.
Dans d’autres domaines, tels que la recherche de connaissances, le modèle est à la traîne par rapport aux meilleurs modèles OpenAI. Les modèles de langage populaires à source ouverte, tels que LLaMA de Meta avec 65 milliards de paramètres, sont moins performants qu’InternLM dans les tests de référence.
L’équipe n’a pas encore publié le modèle de langage, seule la documentation technique est disponible. Cependant, l’équipe écrit sur Github qu’elle prévoit de partager davantage avec la communauté à l’avenir, sans fournir de détails.
Quoi qu’il en soit, InternLM offre un aperçu intéressant de l’état actuel de la recherche chinoise en matière de modélisation linguistique à grande échelle, en supposant que le National AI Laboratory et SenseTime ont réalisé leur meilleur travail à ce jour. « Il reste encore beaucoup de chemin à parcourir pour atteindre un niveau d’intelligence plus élevé », écrit l’équipe de recherche.
