
Le 3D-LLM intègre la compréhension des environnements en 3D dans de grands modèles de langage, permettant aux chatbots de passer du monde bidimensionnel au monde tridimensionnel.
Les grands modèles de langage et les modèles de langage multimodaux peuvent traiter la parole et les images 2D, comme ChatGPT, GPT-4 et Flamingo. Cependant, ces modèles manquent d’une véritable compréhension des environnements en 3D et des espaces physiques. Des chercheurs ont proposé une nouvelle approche appelée 3D LLMs pour résoudre ce problème.
Les 3D LLMs sont conçus pour donner à l’IA une idée des espaces tridimensionnels en utilisant des données en 3D, telles que des nuages de points en entrée. De cette manière, les modèles de langage multimodaux peuvent comprendre des concepts tels que les relations spatiales, la physique et les affordances qui sont difficiles à appréhender uniquement avec des images 2D. Les 3D LLMs pourraient permettre aux assistants IA de mieux naviguer, planifier et agir dans des mondes en 3D, par exemple, en robotique et en IA embarquée.
La relation entre le monde 3D et le langage
Pour entraîner les modèles, l’équipe a dû collecter un nombre suffisant de paires de données en 3D et de langage naturel – de tels ensembles de données sont limités par rapport aux paires d’images et de texte disponibles sur le Web. Par conséquent, l’équipe a développé des techniques de stimulation pour ChatGPT afin de générer différentes descriptions et dialogues en 3D.
Le résultat est un ensemble de données avec plus de 300 000 exemples de texte en 3D, couvrant des tâches telles que l’étiquetage en 3D, la réponse à des questions visuelles, la décomposition des tâches et la navigation. Par exemple, on a demandé à ChatGPT de décrire une scène de chambre en 3D en posant des questions sur les objets visibles sous différents angles.

L’équipe relie les descriptions textuelles aux points dans l’espace 3D
Ensuite, ils ont développé des extracteurs de caractéristiques en 3D pour convertir les données en 3D dans un format compatible avec les modèles de langage pré-entraînés en vision 2D, tels que BLIP-2 et Flamingo.
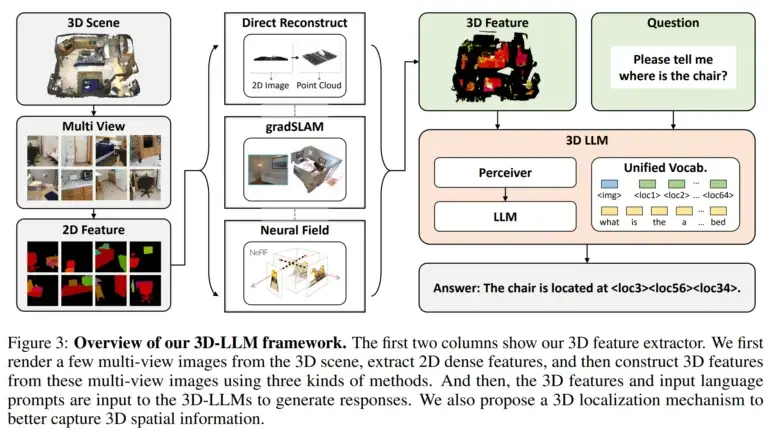
En outre, les chercheurs ont utilisé un mécanisme de localisation en 3D qui permet aux modèles de capturer des informations spatiales en associant des descriptions textuelles à des coordonnées en 3D. Cela a également facilité l’utilisation de modèles tels que BLIP-2 pour entraîner efficacement les LLMs en 3D à comprendre les scènes en 3D.
Les tests avec le modèle de langage 3D ont montré des résultats prometteurs
Les expériences ont démontré que les modèles de langage 3D étaient capables de générer des descriptions en langage naturel de scènes en 3D, de mener des dialogues conscients en 3D, de décomposer des tâches complexes en actions en 3D et de relier le langage à des emplacements spatiaux. Cela démontre le potentiel de l’IA à développer une perception plus humaine des environnements en 3D, en incorporant des capacités de raisonnement spatial, selon les chercheurs.
Les chercheurs ont l’intention d’étendre les modèles à d’autres modalités de données, telles que le son, et de les entraîner à accomplir des tâches supplémentaires. Ils affirment également que l’objectif est d’appliquer ces avancées à des assistants d’IA intégrés capables d’interagir intelligemment avec des environnements en 3D. Avec le contenu de The Decoder.
