
O modelo de linguagem de código aberto FalconLM oferece melhor desempenho do que o LLaMA da Meta e também pode ser usado comercialmente. No entanto, o uso comercial está sujeito ao pagamento de royalties se a receita exceder 1 milhão de dólares.
O FalconLM está sendo desenvolvido pelo Technology Innovation Institute (TII) em Abu Dhabi, Emirados Árabes Unidos. A organização afirma que o FalconLM é o modelo de linguagem de código aberto mais poderoso até o momento, embora a sua maior variante, com 40 bilhões de parâmetros, seja significativamente menor do que o LLaMA da Meta, que possui 65 bilhões de parâmetros.
No Hugging Face OpenLLM Leaderboard, que resume os resultados de vários benchmarks, os dois maiores modelos do FalconLM, sendo que um deles foi refinado com instruções, ocupam atualmente as duas primeiras posições com uma margem significativa. O TII também oferece um modelo de 7 bilhões de parâmetros.
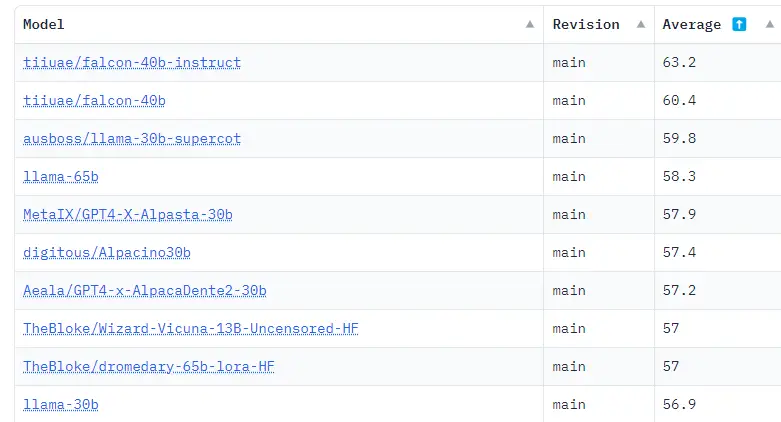
FalconLM treina de forma mais eficiente do que o GPT-3
Um aspecto importante da vantagem competitiva do FalconLM, de acordo com a equipe de desenvolvimento, é a seleção de dados para treinamento. Modelos de linguagem são sensíveis à qualidade dos dados durante o treinamento.
A equipe de pesquisa desenvolveu um processo para extrair dados de alta qualidade do conhecido conjunto de dados Common Crawl e remover duplicatas. Apesar dessa limpeza minuciosa, permaneceram cinco trilhões de fragmentos de texto (tokens) – o suficiente para treinar modelos de linguagem poderosos. A janela de contexto é de 2048 tokens, um pouco abaixo do nível do ChatGPT.
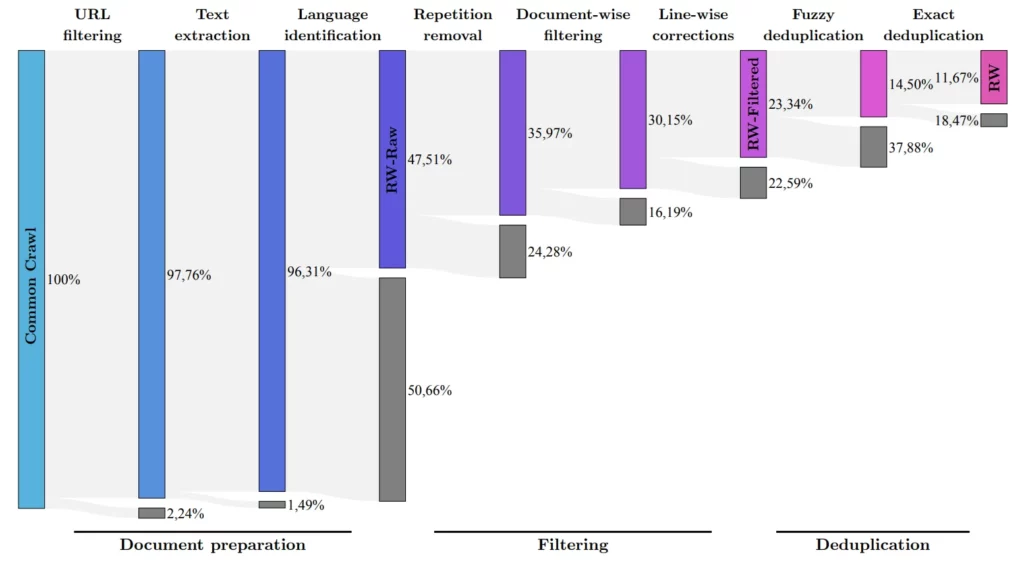
O FalconLM com 40 bilhões de parâmetros foi treinado com um trilhão de tokens, enquanto o modelo com 7 bilhões de parâmetros foi treinado com 1,5 trilhão de tokens. Os dados do conjunto de dados RefinedWeb foram enriquecidos com “alguns” conjuntos de dados selecionados de artigos científicos e discussões em redes sociais. A versão com melhor desempenho, a versão de chatbot, foi refinada usando o conjunto de dados Baize.
O TII também menciona uma arquitetura otimizada para desempenho e eficiência, mas não fornece detalhes. O artigo ainda não está disponível.
Segundo a equipe, a arquitetura otimizada combinada com o conjunto de dados de alta qualidade resultou no FalconLM exigindo apenas 75% do esforço computacional do GPT-3 durante o treinamento, mas superando significativamente o modelo mais antigo da OpenAI. Os custos de inferência são ditos ser um quinto do GPT-3.
Disponível como código aberto, mas o uso comercial pode ser caro
Os casos de uso do TII para o FalconLM incluem geração de texto, solução de problemas complexos, uso do modelo como um chatbot pessoal ou em áreas comerciais, como atendimento ao cliente ou tradução.
Em aplicações comerciais, no entanto, o TII deseja lucrar com um milhão de dólares em receita que pode ser atribuída ao modelo de linguagem: dez por cento das receitas são devidos como royalties. Qualquer pessoa interessada em uso comercial deve entrar em contato com o departamento de vendas do TII. Para uso pessoal e pesquisa, o FalconLM é gratuito.
Todas as versões dos modelos FalconLM estão disponíveis para download gratuito no Huggingface. Juntamente com os modelos, a equipe também está lançando uma parte do conjunto de dados “RefinedWeb” com 600 bilhões de tokens de texto como código aberto sob uma licença Apache 2.0. Diz-se também que o conjunto de dados está pronto para extensão multimodal, uma vez que os exemplos já incluem links e texto alternativo para imagens.
