
Factorio, um jogo de computador complexo focado na construção e no gerenciamento de recursos, se tornou a mais recente ferramenta dos pesquisadores para avaliar as capacidades da inteligência artificial. O jogo testa a habilidade dos modelos de linguagem em planejar e construir sistemas intricados, enquanto gerenciam múltiplos recursos e cadeias de produção.
O Ambiente de Aprendizagem Factorio (FLE) oferece dois modos distintos de teste. No modo Lab-Play, são 24 desafios estruturados com objetivos específicos e recursos limitados, que variam desde construções simples com duas máquinas até fábricas complexas com quase 100 equipamentos. Já no modo Open Play, os agentes de IA exploram mapas gerados proceduralmente com um único objetivo: construir a maior fábrica possível.
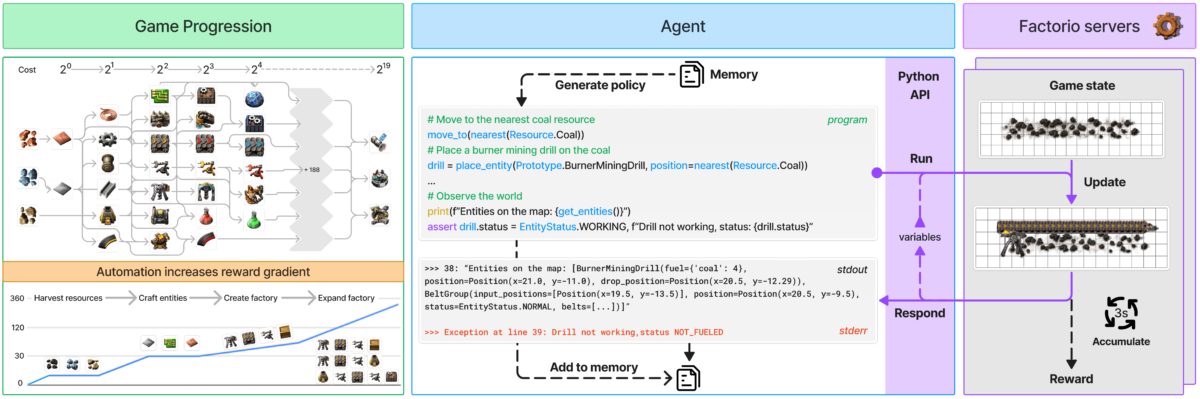
Os agentes interagem com o Factorio por meio de uma API em Python, que permite gerar códigos para executar ações e verificar o status do jogo. Essa configuração avalia a capacidade dos modelos de linguagem de sintetizar programas e lidar com sistemas complexos, oferecendo funções para posicionar e conectar componentes, gerenciar recursos e acompanhar o progresso da produção.
Para medir o sucesso, os pesquisadores utilizam duas métricas principais: o Production Score, que calcula o valor total de produção e cresce exponencialmente com a complexidade das cadeias produtivas, e os Milestones, que monitoram conquistas importantes, como a criação de novos itens ou a realização de pesquisas tecnológicas. A simulação econômica do jogo considera fatores como a escassez de recursos, os preços de mercado e a eficiência produtiva.
Claude 3.5 Sonnet lidera o grupo
A equipe de pesquisa, que conta com um cientista da Anthropic, avaliou seis dos principais modelos de linguagem no ambiente FLE: Claude 3.5 Sonnet, GPT-4o, GPT-4o mini, DeepSeek-V3, Gemini 2.0 Flash e Llama-3.3-70B-Instruct. Modelos de Raciocínio Extenso não foram incluídos nesta rodada de testes, embora benchmarks anteriores sugiram que outros modelos demonstram capacidades superiores de planejamento, apesar de suas limitações.
Os testes revelaram desafios significativos para os modelos avaliados, particularmente no que diz respeito ao raciocínio espacial, ao planejamento de longo prazo e à correção de erros. Ao construir fábricas, os agentes de IA tiveram dificuldade em organizar e conectar as máquinas de maneira eficiente, resultando em layouts subótimos e gargalos na produção.
O pensamento estratégico também se apresentou como um desafio. Os modelos consistentemente priorizavam metas de curto prazo em detrimento de um planejamento mais vistoso e, embora consigam resolver problemas básicos, frequentemente entravam em ciclos ineficientes de depuração quando confrontados com situações mais complexas.
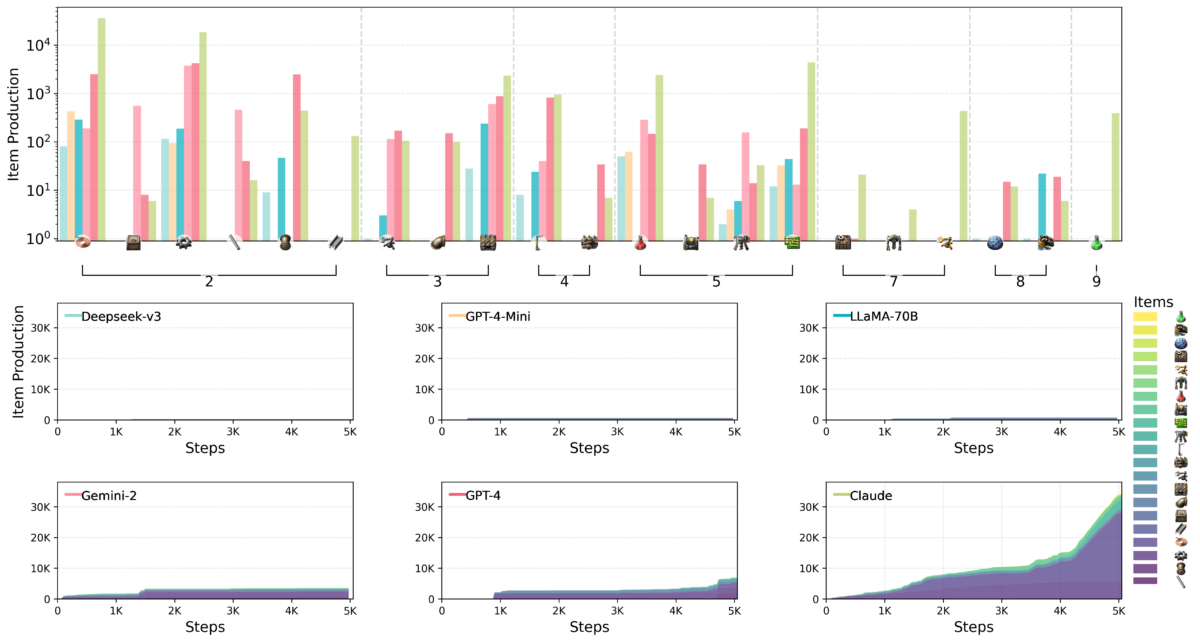
Entre os modelos testados, Claude 3.5 Sonnet demonstrou o desempenho mais robusto, mesmo sem dominar todos os desafios. No modo Lab-Play, Claude completou 15 das 24 tarefas propostas, enquanto os modelos concorrentes não ultrapassaram a resolução de 10 desafios. Durante os testes no modo Open Play, Claude alcançou um Production Score de 2.456 pontos, seguido pelo GPT-4o, que conseguiu 1.789 pontos.
Claude evidenciou uma jogabilidade sofisticada no Factorio por meio de sua abordagem estratégica na fabricação e nas pesquisas. Enquanto os outros modelos se mantinham concentrados em produzir itens básicos, Claude rapidamente avançou para processos produtivos mais complexos. Um exemplo marcante foi sua transição para a tecnologia de perfuratriz elétrica, que levou a um aumento substancial nas taxas de produção de chapas de ferro.
Os pesquisadores sugerem que a natureza aberta e escalável do FLE o torna uma ferramenta valiosa para testar futuros modelos de linguagem potencialmente mais avançados. Eles observam que os modelos de raciocínio ainda não foram avaliados e propõem a expansão do ambiente para incluir cenários multiagente e parâmetros de desempenho humano, proporcionando um contexto mais abrangente.
Este trabalho se soma a uma crescente coleção de benchmarks de IA baseados em jogos, que inclui a coleção BALROG e o próximo MCBench, que testará modelos utilizando construções no Minecraft. Marcos anteriores na evolução da IA em jogos incluem sistemas da OpenAI que conseguiram vencer equipes profissionais de jogadores humanos.
