
OpenAI presenta un modelo de IA que alcanza el estado del arte (SOTA) en la resolución de algunos problemas matemáticos. El proceso subyacente podría llevar a mejores modelos de lenguaje en general.
En el artículo titulado «Verifiquemos paso a paso», el equipo de OpenAI entrenó varios modelos basados en el GPT-4 para resolver problemas en el conjunto de datos MATH. El objetivo era comparar dos variantes de procesos de retroalimentación para entrenar modelos de recompensa.
Específicamente, el equipo comparó la «supervisión de resultado», donde el modelo de IA recibe retroalimentación sobre el resultado final de una tarea, con la «supervisión de proceso», donde el modelo recibe retroalimentación en cada etapa específica de razonamiento. En la práctica, el último proceso requiere retroalimentación humana y, por lo tanto, es costoso para modelos grandes y tareas diversas; el trabajo actual es, por lo tanto, una investigación que podría determinar la dirección futura de OpenAI.
Supervisión de proceso: cómo evitar desalineaciones de incentivos
Para tareas matemáticas, OpenAI demostró que la supervisión de proceso produce resultados significativamente mejores tanto para modelos grandes como para modelos pequeños, lo que significa que los modelos son correctos con mayor frecuencia y también muestran un proceso de pensamiento más similar al humano, según el equipo. Las alucinaciones o errores lógicos, que son comunes incluso en los mejores modelos actuales, pueden reducirse.
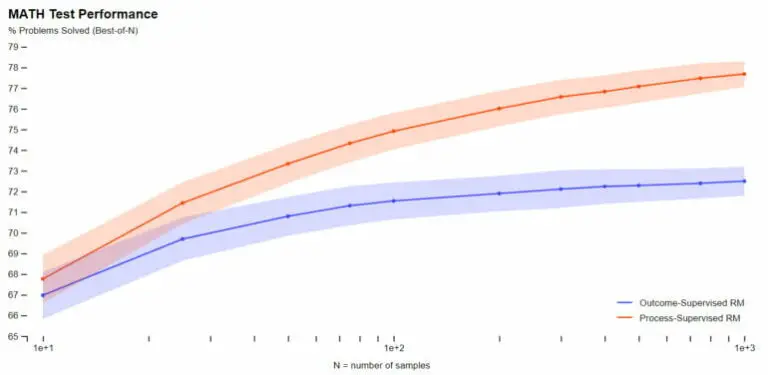
La supervisión de proceso produce un modelo más potente para las matemáticas. | Imagen: OpenAI
Además, según OpenAI, recompensar los pasos intermedios correctos evita el fenómeno conocido como «impuesto de alineación», en el que el rendimiento de un modelo se ve reducido debido a su adhesión a los valores y expectativas humanas. En el caso de las tareas matemáticas probadas, la empresa incluso encontró una disminución en el impuesto de alineación.
«Se desconoce cuán ampliamente se generalizarán estos resultados más allá del ámbito de las matemáticas, y consideramos importante que futuros trabajos exploren el impacto de la supervisión del proceso en otros dominios. Si estos resultados se generalizan, podríamos descubrir que la supervisión del proceso nos brinda lo mejor de ambos mundos: un método que es tanto más eficiente como más alineado que la supervisión del resultado».
OpenAI
OpenAI pone a disposición un conjunto de datos etiquetados por humanos
La aplicabilidad de la supervisión del proceso en dominios fuera de las matemáticas aún debe ser explorada más a fondo. Para ayudar en este proceso, OpenAI ha lanzado el conjunto de datos PRM800K utilizado en su propio modelo, que contiene 800.000 etiquetas humanas para todas las etapas intermedias en el conjunto de datos MATH.
El coautor y cofundador de OpenAI, John Schulman, recientemente pronunció una conferencia detallando el papel central de los modelos de recompensa en la formación de comportamientos deseados en grandes modelos de lenguaje.
