
MosaicML ha lanzado el mejor modelo de lenguaje de código abierto hasta la fecha, con licencia para uso comercial. Una de sus variantes incluso puede manejar libros completos.
El MPT-7B de MosaicML es un modelo de lenguaje de gran envergadura con casi 7 mil millones de parámetros, que el equipo entrenó en su propio conjunto de datos de casi un billón de tokens.
MosaicML siguió el régimen de entrenamiento del modelo LLaMA de Meta. El entrenamiento costó casi 200,000 dólares y llevó 9.5 días utilizando la plataforma MosaicML.
El MPT-7B de MosaicML es el mejor modelo de código abierto hasta la fecha.
Según MosaicML, el MPT-7B se equipara al rendimiento del modelo LLaMA de 7 mil millones de parámetros de Meta, convirtiéndose en el primer modelo de código abierto en alcanzar este nivel, superando a OpenLLaMA.
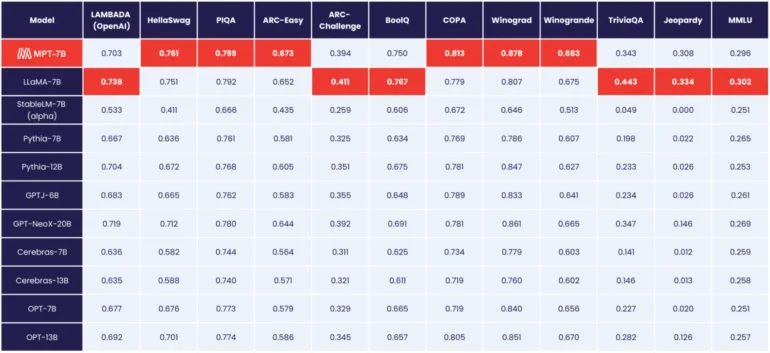
A diferencia de los modelos de Meta, el MPT-7B tiene una licencia para uso comercial.
Además del modelo «MPT-7B Base», MosaicML también lanza tres variantes: MPT-7B-StoryWriter-65k+, MPT-7B-Instruct y MPT-7B-Chat.
MosaicML lanza un modelo de lenguaje con un contexto de 65.000 tokens
El MPT-7B-Instruct es un modelo diseñado para seguir instrucciones, mientras que el modelo Chat es una variante de chatbot al estilo Alpaca o Vicuna.
Con el MPT-7B-StoryWriter-65k+, MosaicML también presenta un modelo capaz de leer y escribir historias con longitudes de contexto muy extensas. Para este propósito, el MPT-7B fue ajustado con un contexto de 65.000 tokens utilizando un subconjunto del conjunto de datos books3. La variante GPT-4 más grande de OpenAI puede manejar 32.000 tokens.
Según MosaicML, el modelo puede escalar más allá de los 65.000 tokens con algunas optimizaciones, y el equipo demostró incluso 84.000 tokens en un solo nodo utilizando GPUs Nvidia A100-80GB. Pero incluso con 65.000 tokens, era posible leer novelas completas y escribir un epílogo.

Todos los modelos MPT-7B están disponibles en GitHub.
