
En cierta forma, los humanos y los grandes modelos de lenguaje parecen exhibir comportamientos similares: responden particularmente bien a la información al principio o al final de un contenido. La información en el medio tiende a perderse.
Investigadores de la Universidad de Stanford, de la Universidad de California, Berkeley, y de Samaya AI descubrieron un efecto en LLMs (Large Language Models) que recuerda al efecto de primacía/recencia conocido en humanos. Esto significa que las personas tienden a recordar el contenido al principio y al final de una declaración. El contenido en el medio tiende a ser ignorado.
Según el estudio, un efecto similar ocurre con los grandes modelos de lenguaje: cuando se les solicita recuperar información de una entrada, los modelos tienen un mejor rendimiento cuando la información se encuentra al principio o al final de la entrada.
Sin embargo, cuando la información relevante está en el medio de la entrada, el rendimiento disminuye significativamente. Esta disminución en el rendimiento es particularmente pronunciada cuando se les pide al modelo que responda a una pregunta que requiere extraer información de múltiples documentos, equivalente a un estudiante que debe identificar información relevante de varios libros para responder a una pregunta en un examen.
Cuanto mayor sea la cantidad de entrada que el modelo necesita procesar simultáneamente, peor será su rendimiento. Esto puede ser un problema en escenarios del mundo real donde es importante procesar grandes cantidades de información de forma simultánea y equitativa.
Los resultados también sugieren que hay un límite en cuán efectivamente los grandes modelos de lenguaje pueden utilizar información adicional, y que las «mega-instrucciones» con instrucciones particularmente detalladas probablemente harán más mal que bien.
¿Qué tan útiles son los LLMs con grandes ventanas de contexto?
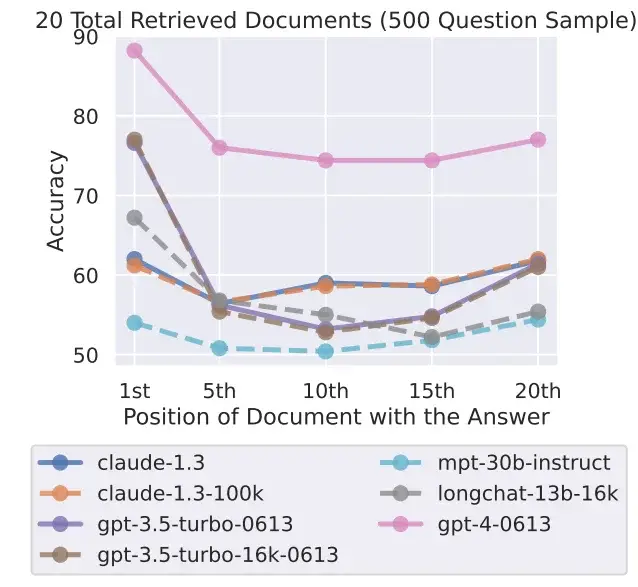
El fenómeno de «pérdida en el medio» también ocurre con modelos diseñados específicamente para manejar muchos contextos, como GPT-4 32K o Claude con su ventana de contexto de 100.000 tokens.
Los investigadores probaron siete modelos de lenguaje abiertos y cerrados, incluidos el nuevo GPT-3.5 16K y Claude 1.3 con 100K. Todos los modelos mostraron una curva en forma de U más o menos pronunciada, dependiendo de la prueba, con un mejor rendimiento en tareas donde la solución se encuentra al principio o al final del texto.

Eso plantea la cuestión de la utilidad de modelos con una gran ventana de contexto cuando se pueden obtener mejores resultados al procesar el contexto en fragmentos más pequeños. El actual modelo líder, el GPT-4, también muestra este efecto, pero a un nivel de rendimiento general más alto.
Es cierto que el equipo de investigación reconoce que todavía no se comprende completamente cómo los modelos procesan el lenguaje. Esta comprensión necesita ser mejorada a través de nuevos métodos de evaluación, y también puede requerir nuevas arquitecturas.
Además, los investigadores afirman que hay una necesidad de estudiar cómo el diseño de los «prompts» afecta el rendimiento del modelo. Hacer que los sistemas de IA sean más conscientes de la tarea específica en un «prompt» podría mejorar su capacidad para extraer información relevante.
