
Con AudioPaLM, Google añade funciones de audio a su gran modelo lingüístico PaLM-2. Esto permite realizar traducciones habladas con la voz del hablante original.
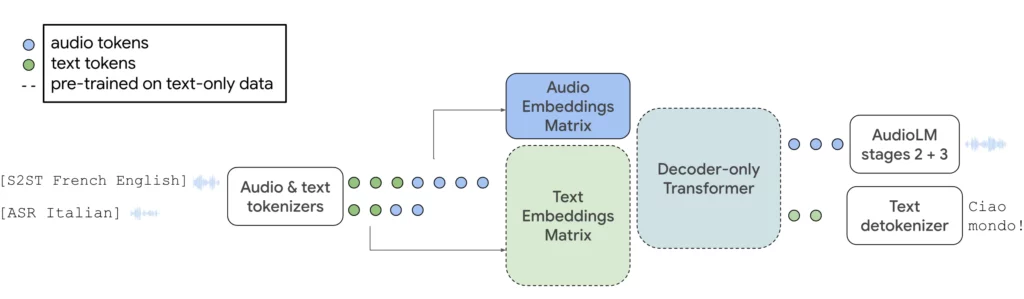
Con AudioPaLM, Google combina el gran modelo lingüístico PaLM-2, presentado en mayo, con su modelo generativo de audio AudioLM en una arquitectura multimodal central. El sistema puede procesar y generar texto y voz, y puede utilizarse para el reconocimiento de voz o para generar traducciones con voces originales.
Babelfish se acerca
La última característica es especialmente notable, ya que permite a una persona hablar en varios idiomas simultáneamente, como se muestra en la siguiente demostración.
El acondicionamiento para la voz original sólo requiere una muestra de tres segundos, proporcionada como un audio y un token SoundStream. Si el archivo de audio es más corto, se repetirá hasta alcanzar los tres segundos.
Al integrar AudioLM, AudioPaLM puede producir audio de alta calidad con consistencia a largo plazo. Esto incluye la capacidad de generar continuaciones del habla semánticamente plausibles, preservando la identidad del locutor y la prosodia de los locutores no vistos durante el entrenamiento.
El modelo también puede realizar traducciones de voz a texto sin formación previa en muchos idiomas, incluidas combinaciones de habla que no se encontraron durante el entrenamiento. Esta capacidad puede ser importante para aplicaciones reales, como la comunicación multilingüe en tiempo real.
AudioPaLM también conserva la información paralingüística, como la identidad del hablante y la entonación, que suelen perderse en los sistemas tradicionales de traducción de voz a texto. Se espera que el sistema supere a las soluciones existentes en cuanto a calidad del habla, según evaluaciones tanto automáticas como humanas.
Además de generar voz, AudioPaLM también puede generar transcripciones, ya sea en la lengua original o directamente como traducción, o generar voz en la lengua de origen. AudioPaLM obtuvo los mejores resultados en pruebas comparativas de traducción de voz y demostró un rendimiento competitivo en tareas de reconocimiento de voz.
De los asistentes de voz al multilingüismo automatizado
Las aplicaciones potenciales son muchas: asistentes de voz multilingües, servicios de transcripción automática y cualquier otro sistema que necesite entender o generar lenguaje humano escrito o hablado.
Google podría encontrar casos de uso para vídeos multilingües generados por IA, especialmente en YouTube: por ejemplo, podría ayudar a crear subtítulos multilingües o doblar vídeos a varios idiomas sin perder la voz del hablante original.
Los investigadores señalan varias áreas de investigación futura, entre ellas la comprensión de las propiedades óptimas de las fichas de audio y cómo medirlas y optimizarlas. También subrayan la necesidad de establecer parámetros y métricas para las tareas de audio generativo, lo que ayudaría a acelerar la investigación en este campo.
Más información y demostraciones en la página GitHub del proyecto.
