
El modelo de lenguaje de código abierto FalconLM supera al LLaMA de Meta y también puede ser utilizado con fines comerciales. Sin embargo, el uso comercial está sujeto al pago de regalías si los ingresos superan 1 millón de dólares.
El FalconLM está siendo desarrollado por el Technology Innovation Institute (TII) en Abu Dhabi, Emiratos Árabes Unidos. La organización afirma que el FalconLM es el modelo de lenguaje de código abierto más potente hasta la fecha, aunque su variante más grande, con 40 mil millones de parámetros, es significativamente menor que el LLaMA de Meta, que cuenta con 65 mil millones de parámetros.
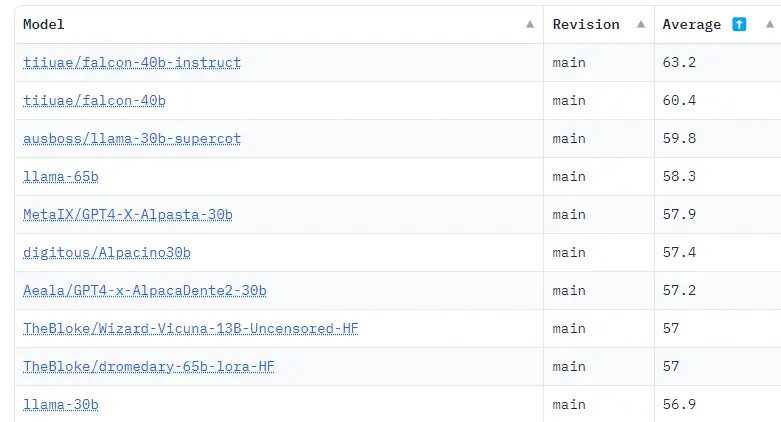
En la clasificación Hugging Face OpenLLM Leaderboard, que resume los resultados de varios benchmarks, los dos modelos más grandes de FalconLM, uno de los cuales fue refinado con instrucciones, ocupan actualmente los dos primeros lugares con una diferencia significativa. El TII también ofrece un modelo de 7 mil millones de parámetros.
FalconLM se entrena de manera más eficiente que GPT-3
Un aspecto importante de la ventaja competitiva de FalconLM, según el equipo de desarrollo, es la selección de datos para el entrenamiento. Los modelos de lenguaje son sensibles a la calidad de los datos durante el entrenamiento.
El equipo de investigación ha desarrollado un proceso para extraer datos de alta calidad del conocido conjunto de datos Common Crawl y eliminar duplicados. A pesar de esta limpieza exhaustiva, quedaron cinco billones de fragmentos de texto (tokens), lo cual es suficiente para entrenar modelos de lenguaje poderosos. La ventana de contexto consta de 2048 tokens, un poco menos que el nivel de ChatGPT.
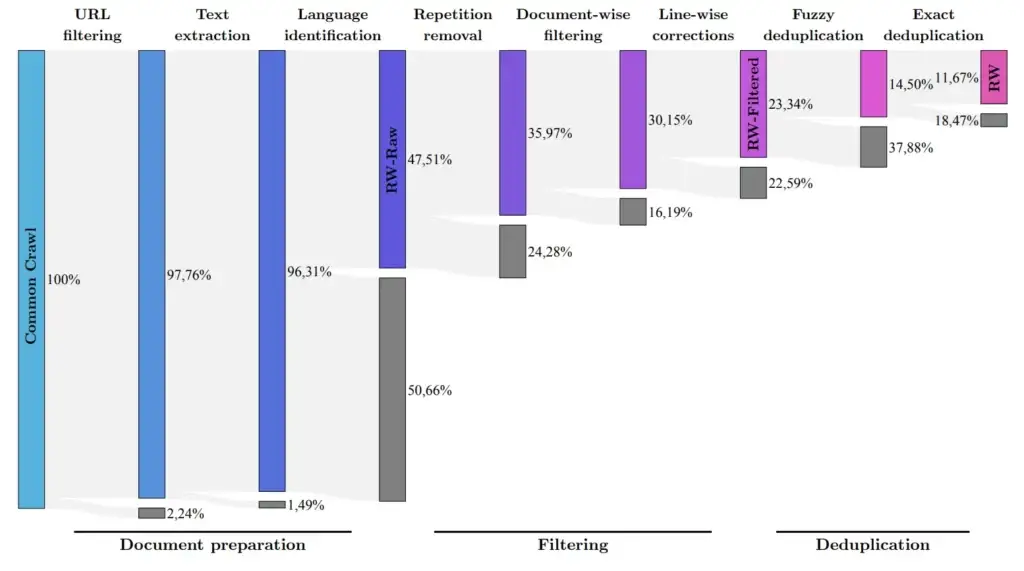
El objetivo del equipo de investigación es utilizar el conjunto de datos RefinedWeb para filtrar solo los datos originales de mayor calidad de Common Crawl. | Imagen: TII
El FalconLM con 40 mil millones de parámetros fue entrenado con un billón de tokens, mientras que el modelo con 7 mil millones de parámetros fue entrenado con 1,5 billones de tokens. Los datos del conjunto de datos RefinedWeb se enriquecieron con «algunos» conjuntos de datos seleccionados de artículos científicos y discusiones en redes sociales. La versión de mejor rendimiento, la versión de chatbot, se refinó utilizando el conjunto de datos Baize.
El TII también menciona una arquitectura optimizada para rendimiento y eficiencia, pero no proporciona detalles. El artículo aún no está disponible.
Según el equipo, la arquitectura optimizada combinada con el conjunto de datos de alta calidad resultó en que el FalconLM requiriera solo el 75% del esfuerzo computacional del GPT-3 durante el entrenamiento, pero superara significativamente al modelo más antiguo de OpenAI. Los costos de inferencia se dice que son una quinta parte del GPT-3.
Disponible como código abierto, pero el uso comercial puede ser costoso
Los casos de uso del TII para el FalconLM incluyen generación de texto, resolución de problemas complejos, uso del modelo como un chatbot personal o en áreas comerciales como servicio al cliente o traducción.
Sin embargo, en aplicaciones comerciales, el TII busca obtener ganancias a partir de un millón de dólares en ingresos que se puedan atribuir al modelo de lenguaje: el diez por ciento de los ingresos se deben pagar como regalías. Cualquier persona interesada en uso comercial debe ponerse en contacto con el departamento de ventas del TII. Para uso personal e investigación, el FalconLM es gratuito.
Todas las versiones de los modelos FalconLM están disponibles para descarga gratuita en Huggingface. Junto con los modelos, el equipo también está lanzando una parte del conjunto de datos «RefinedWeb» con 600 mil millones de tokens de texto como código abierto bajo una licencia Apache 2.0. También se dice que el conjunto de datos está listo para la extensión multimodal, ya que los ejemplos ya incluyen enlaces y texto alternativo para imágenes.
