
Utilizando Google Bard como ejemplo, el colaborador invitado Aditya Anil explica cómo las ideas de Daniel Kahneman pueden ayudar a crear mejores chatbots.
«Pensar rápido y despacio» es un best seller del New York Times escrito por el psicólogo y premio Nobel Daniel Kahneman. El libro presenta su hipótesis sobre cómo y qué impulsa nuestro pensamiento.
Esta hipótesis está siendo aprovechada actualmente por los chatbots de IA, como Bard de Google, para ser más eficientes y precisos.
Pero, ¿cómo ayuda exactamente la hipótesis de Daniel Kahneman recogida en el libro a desarrollar los chatbots de IA?
Los dos sistemas que dirigen el pensamiento

Comparte nuestro artículo
Recomendar nuestro artículoCompartir
El libro de Kaheman explora dos sistemas de pensamiento
- el pensamientobasado en la intuición (que se denomina pensamiento del Sistema 1) y
- el pensamientolento (llamado pensamiento del Sistema 2).
Según Kaheman, el Sistema 1 es rápido, visceral y emocional, mientras que el Sistema 2 es lento, deliberativo y lógico. Aunque ambos sistemas desempeñan un papel crucial en la toma de decisiones, uno tiende a ser más activo que el otro dependiendo de la situación.
El Sistema 1 funciona rápidamente y sin esfuerzo. La acción en este sistema requiere poco o ningún esfuerzo, sin sensación de control voluntario.
Esto incluye acciones como leer palabras en un cartel, detectar si un objeto está lejos o cerca en relación con otro objeto, identificar un sonido que se oye, etc.
El Sistema 2, en cambio, es más consciente y lógico. Las acciones de este sistema llevan mucho tiempo, con controles voluntarios. Este sistema se activa cuando se llevan a cabo pensamientos abstractos y lógicos.
Esto incluye acciones como identificar a alguien en una multitud, hacer largos cálculos mentalmente, jugar al ajedrez, etc.
Recientemente, el concepto de dos sistemas está siendo utilizado por Bard (el chatbot de inteligencia artificial de Google) para mejorar sus operaciones matemáticas y de cuerdas, haciendo que su respuesta sea más dinámica y precisa.
Pero, ¿cómo utiliza Bard este concepto psicológico para mejorar su propio sistema de IA?
Cómo los principios del pensamiento ayudan a la IA
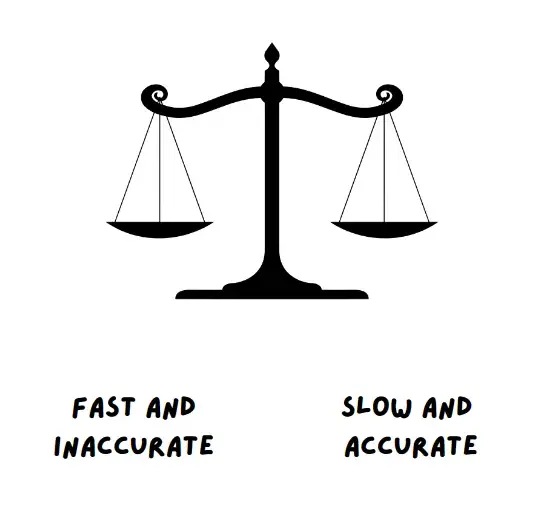
Antes de profundizar en el tema, entendamos las principales ventajas e inconvenientes de cada sistema.
El libro hace hincapié en que el pensamiento del Sistema 1 es responsable del 98% y de todo nuestro pensamiento, mientras que el pensamiento del Sistema 2 es responsable del 2% restante y es un esclavo del Sistema 1 y es esclavo del Sistema 1.
Pero ambos sistemas tienen sus ventajas e inconvenientes e influyen mucho en nuestra capacidad para tomar decisiones.
Desventajas de cada sistema
Confiar demasiado en el pensamiento del Sistema 1 puede conducir a sesgos y errores. Algunas de las advertencias del pensamiento del Sistema 1 son las siguientes:
- Gran indulgencia con el sesgo de confirmación
- Tendencia a ignorar detalles concretos e importantes
- Ignorar las pruebas que no nos gustan, lo que conduce a la ignorancia
- Pensar demasiado decisiones aparentemente simples o irrelevantes
- Producir justificaciones cuestionables para malas decisiones
etc.
Por otra parte, confiar demasiado en el pensamiento del Sistema 2 también puede conducir a errores y consecuencias negativas. Por ejemplo
- Pensar demasiado las decisiones sencillas y perder demasiado tiempo
- Incapacidad para tomar decisiones rápidas
- Ser demasiado escéptico y retener demasiado el juicio
- Fatiga en la toma de decisiones y sobrecarga cognitiva
- Tomar decisiones muy lógicas y no tener en cuenta las emociones
Pensamiento de dos sistemas: aplicado a la IA
Aunque en el ámbito humano esto es muy psicológico, las cosas se ponen bastante interesantes cuando este concepto se aplica a la IA y la informática.
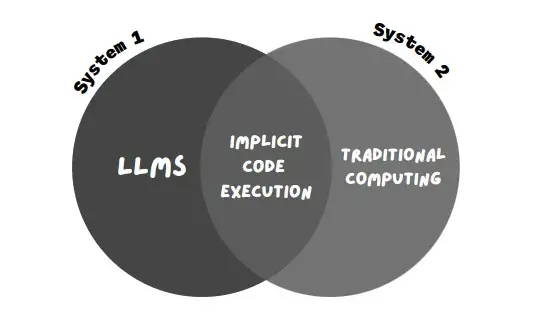
Se puede considerar que los LLM (el modelo de IA que utilizan chatbots como Bard y CHatGPT) funcionan en el Sistema 1. ¿Cómo?
¿Cómo?
Los LLM (los modelos de IA que hacen funcionar estos chatbots) funcionan encontrando patrones en los miles de millones de datos de entrenamiento con los que han sido entrenados previamente y generan una respuesta que coincide con el patrón común. Por ejemplo, cuando le dices a un chatbot «escribe una redacción sobre el cambio climático», el proceso en el backend es el siguiente
- Busca consultas coincidentes en su amplia base de datos de entrenamiento. El chatbot intenta encontrar una consulta común que incluya las palabras clave «cambio climático» y «redacción».
- Busca unatendencia o patrón. A continuación, el chatbot intenta encontrar una tendencia o patrón común entre todos los datos seleccionados. Por ejemplo, el patrón podría ser que casi todos los datos mencionen «emisiones de carbono», «huella de carbono», «contaminación por plástico», «calentamiento global», etc. Además, los formatos de título y párrafo de los ensayos también son un estándar en sí mismos (en contraste con otros formatos como poemas, blogs, etc.).
- Generar un texto conforme a la norma. Esta es la parte divertida. Piense en este proceso como en la resolución de un puzzle.
El bot intenta generar el texto utilizando los bits de datos (las piezas del puzzle) e intenta que se parezca al patrón de un ensayo similar (las imágenes finales), que en este caso es un ensayo sobre el cambio climático. Crea varias iteraciones (es decir, salidas) del texto que le has proporcionado y las compara con los datos de referencia, que podrían ser un ensayo ya escrito sobre el cambio climático. - Proporcionael resultado. Se elige la iteración que más se acerca al resultado deseado y se imprime en la pantalla.
Este proceso puede parecer largo, pero sólo tarda unos segundos en ejecutarse en los LLM tradicionales. El primer paso se lleva a cabo mucho antes, en la fase de desarrollo y entrenamiento de un LLM, que consiste en entrenar el modelo de IA en conjuntos de datos que contienen miles de millones de datos. Tras aprender de este enorme conjunto de datos y encontrar el patrón en todos ellos, se completa la parte más pesada y difícil del proceso LLM.
El resto del paso es bastante rápido, en gran parte debido a la calidad de los datos con los que se ha entrenado el modelo. En general, cuanto mejores sean los datos de entrenamiento proporcionados, mejores serán las predicciones y la generación.
Así, el LLM genera textos sin esfuerzo, sin «pensar» demasiado. Simplemente encuentra el patrón y compara el resultado con la referencia.
Por tanto, los LLM se encuentran en el Sistema 1, que es rápido y eficiente. Sin embargo, la desventaja de esto es que los LLM pueden generar resultados incorrectos y sesgados e incluso inventar sus propios hechos y cifras (alucinación AI).
Este es el motivo del siguiente caso, en el que a veces Bard muestra resultados sin esfuerzo para peticiones difíciles, pero falla estrepitosamente en tareas fáciles, como la siguiente
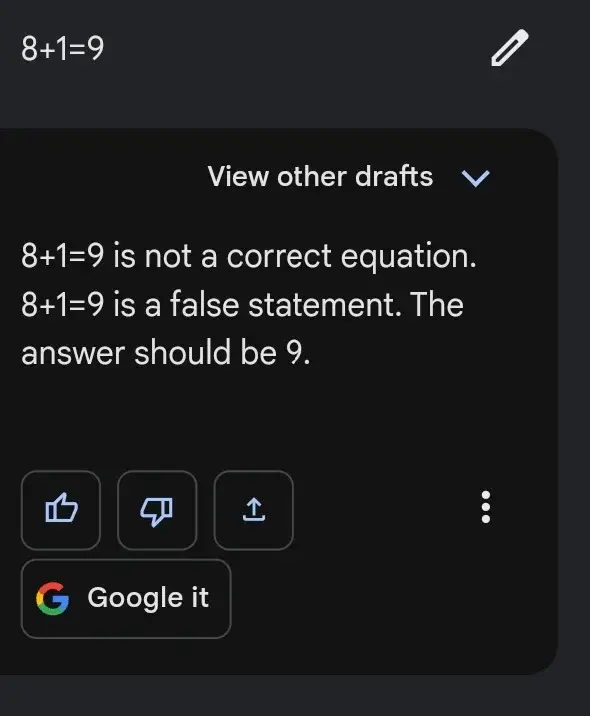
Esto se debe a que la resolución de un determinado problema matemático es eficiente cuando se sigue una secuencia específica de pasos, en lugar de confiar en «patrones» de problemas matemáticos similares.
Aquí es donde mejor funciona la informática tradicional. Por ejemplo, la forma en que funcionan las calculadoras de tu ordenador.
La informática tradicional sigue una secuencia o una estructura, que tiene forma de código o de algoritmo simple. En este sentido, la informática tradicional es preferible para tareas como problemas matemáticos, manejo de operaciones con cadenas, conversiones, etcétera. El inconveniente es que, al seguir un formato específico, no tiene por qué ser rápida o eficiente la mayor parte del tiempo. El ordenador tradicional puede encontrar la respuesta a preguntas como 12*24 = 288, pero tarda más en responder a preguntas relacionadas con cálculos.
Sin embargo, el punto positivo aquí es que es casi seguro que obtenga la respuesta correcta la mayoría de las veces.
Tenga en cuenta que la informática tradicional es bastante lenta, más lógica y estructurada en comparación con las LLM
Así pues, la informática tradicional entra dentro del sistema 2. Es relativamente lenta, mucho más sistemática y lógica. Consiste en un algoritmo, código o cualquier otro sistema de ejecución codificado.
Es interesante observar que Bard, de Google, intenta utilizar ambos sistemas para optimizar la respuesta de su chatbot.
Cómo lo utiliza Bard
Bard tuvo un comienzo difícil cuando se lanzó. El vídeo promocional inicial en el que se mostraba la capacidad de Bard recibió muchas críticas después de que la respuesta consistiera en información errónea.
Por ello, era importante que Bard hiciera que su robot de inteligencia artificial fuera más preciso, con menos sesgos o información errónea. Se trata de un objetivo difícil para reducir la desinformación y aumentar la eficacia en casi todas las herramientas de IA existentes.
Por ello, el 7 de junio Google publicó un blog titulado«Bard está mejorando en lógica y razonamiento«.
El blog destacaba dos nuevas características de Bard.
Una era la función de exportación a Google Sheets, que permite al usuario exportar sus resultados con tablas a Google Sheets.
La otra función permitía a Bard -en sus propias palabras- «mejorar en tareas matemáticas, cuestiones de codificación y manipulación de cadenas»
Antes, Bard tenía dificultades con los problemas matemáticos, y sigue teniéndolas de vez en cuando. Pero utilizando el enfoque de combinar los dos sistemas que he mencionado antes, Bard pretende mejorar ahora corrigiendo sus tontos errores matemáticos.
Esta nueva técnica que utiliza Bard se llama «ejecución implícita de código».
Mientras que los LLM (Sistema 1, que consiste en respuestas rápidas basadas en patrones) reciben la advertencia, la ejecución implícita de código permite a Bard detectar advertencias computacionales (Sistema 2, que consiste en la ejecución lógica y sistemática) y ejecutar código en segundo plano.
Esto ayuda a Bard a proporcionar respuestas a peticiones matemáticas y basadas en cadenas mucho más fácilmente.
En el ejemplo mencionado en el blog, Google dijo que Bard mejorará la respuesta a peticiones como:
- ¿Cuáles son los factores primos de 15683615?
- Calcular la tasa de crecimiento de mis ahorros
- Invertir la palabra «Lollipop» para mí
Los siguientes extractos del blog captan la esencia y la motivación de utilizar este enfoque (de utilizar el enfoque de dos sistemas de pensamiento) – «Como resultado, se desempeñan bien en sus tareas»
«Como resultado, han demostrado ser extremadamente capaces en tareas creativas y lingüísticas, pero más débiles en áreas como el razonamiento y las matemáticas».
Para ayudar a resolver problemas más complejos con capacidades avanzadas de razonamiento y lógica, no basta con basarse únicamente en el resultado del LLM.
Se puede considerar que los LLM funcionan exclusivamente con el Sistema 1, es decir, que producen texto con rapidez pero sin pensar en profundidad…. La informática tradicional se alinea estrechamente con el Sistema 2 de pensamiento: es estereotipada e inflexible, pero la secuencia correcta de pasos puede producir resultados impresionantes, como soluciones a divisiones largas»
– Google en su blog
Este enfoque de mantener las LLM y la computación tradicional en el Sistema 1 y el Sistema 2, respectivamente, garantiza que la respuesta sea mucho más precisa y eficiente.
Utilizando este enfoque, Bard -según el blog- mostró un aumento de casi el 30 de precisión al enfrentarse a problemas de palabras y matemáticas.
¿Hasta qué punto es fiable este nuevo enfoque?
Aunque mejora la precisión de Bard a la hora de resolver problemas matemáticos y de palabras, quizá no sea el mejor enfoque para hacer que el chatbot sea eficiente.
Aunque muestra una precisión significativa cuando se enfrenta a problemas matemáticos y de palabras, sigue teniendo problemas cuando se enfrenta a problemas relacionados con el código.
«Incluso con estas mejoras, Bard no siempre acierta: por ejemplo, es posible que Bard no genere código para ayudar con la respuesta rápida, que el código que genere sea incorrecto o que Bard no incluya el código ejecutado en su respuesta», afirma Google al final del blog.
Así que, aunque se trata de un cambio significativo, Bard todavía tiene que dar un paso más para que se confíe plenamente en él.
Reducir la desinformación y aumentar la eficacia son los retos de casi todos los chatbots existentes.
Aunque se están haciendo progresos, aún queda mucho camino por recorrer. Con información de The Decoder.
