
El InternLM es un gran modelo de lenguaje con 104 mil millones de parámetros introducido por el Laboratorio Nacional de IA de China, el Shanghai AI Lab, en colaboración con la empresa de vigilancia SenseTime.
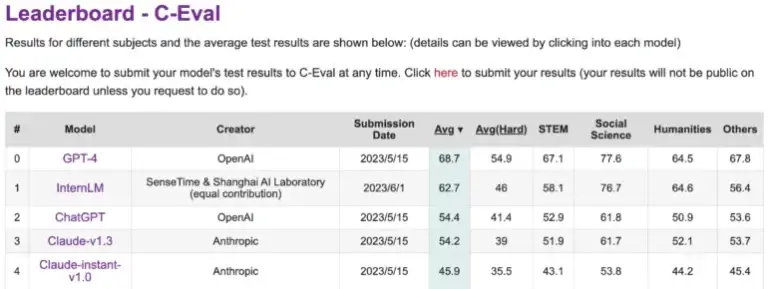
La Universidad China de Hong Kong, la Universidad Fudan y la Universidad Jiaotong de Shanghai también participaron en su desarrollo. En tareas en idioma chino, claramente supera al ChatGPT de OpenAI y al Anthropics Claude.
Sin embargo, se encuentra por detrás del GPT-4 en C-Eval, una plataforma que evalúa el rendimiento de los grandes modelos de lenguaje en chino. El InternLM fue entrenado con 1,6 billones de tokens y, al igual que el GPT-4, fue refinado para satisfacer las necesidades humanas utilizando RLHF y ejemplos seleccionados. Está basado en una arquitectura de transformer similar a la del GPT.
El entrenamiento se basó principalmente en datos del Massive Web Text, enriquecido con enciclopedias, libros, artículos científicos y código. Los investigadores también desarrollaron el sistema de entrenamiento Uniscale LLM, capaz de entrenar de manera confiable grandes modelos de lenguaje con más de 200 mil millones de parámetros en 2048 GPUs utilizando un conjunto de técnicas de entrenamiento paralelo.
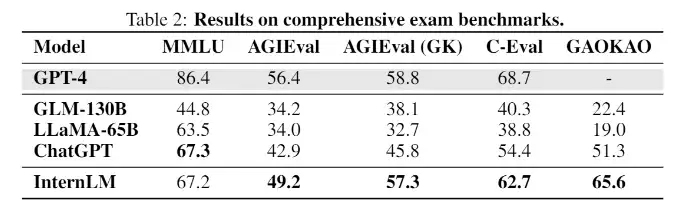
El InternLM logra un rendimiento equivalente al ChatGPT en evaluaciones de exámenes. En evaluaciones con tareas que simulan exámenes humanos, como MMLU, AGIEval, C-Eval y GAOKAO Bench, el InternLM también alcanza un rendimiento comparable al ChatGPT. Sin embargo, se queda por detrás del GPT-4, lo cual los investigadores atribuyen a la pequeña ventana de contexto de solo 2000 tokens.
En otras áreas, como recuperación de conocimiento, el modelo queda por detrás de los mejores modelos de OpenAI. Modelos de lenguaje de código abierto populares, como el LLaMA de Meta con 65 mil millones de parámetros, tienen un rendimiento inferior al del InternLM en las evaluaciones.
El equipo aún no ha publicado el modelo de lenguaje, hasta ahora solo está disponible la documentación técnica. Sin embargo, el equipo escribe en Github que planea compartir más con la comunidad en el futuro, sin proporcionar detalles.
Independientemente de eso, el InternLM ofrece una visión interesante del estado actual de la investigación china en modelos de lenguaje a gran escala, suponiendo que el Laboratorio Nacional de IA y SenseTime hayan realizado su mejor trabajo hasta el momento. «Hacia un nivel más alto de inteligencia, todavía queda un largo camino por recorrer», escribe el equipo de investigación.
