
El 3D-LLM integra la comprensión de entornos en 3D en grandes modelos de lenguaje, llevando a los chatbots del mundo bidimensional al mundo tridimensional.
Los grandes modelos de lenguaje y los modelos de lenguaje multimodales pueden manejar el habla e imágenes 2D, como ChatGPT, GPT-4 y Flamingo. Sin embargo, estos modelos carecen de una comprensión real de entornos en 3D y espacios físicos. Ahora, los investigadores han propuesto un nuevo enfoque llamado 3D LLMs para resolver este problema.
Los 3D LLMs están diseñados para proporcionar a la IA una idea de los espacios tridimensionales utilizando datos en 3D, como nubes de puntos como entrada. De esta manera, los modelos de lenguaje multimodales pueden comprender conceptos como relaciones espaciales, física y capacidades que son difíciles de entender solo con imágenes 2D. Los 3D LLMs podrían permitir que los asistentes de IA naveguen, planifiquen y actúen mejor en mundos en 3D, por ejemplo, en robótica e IA integrada.
La relación entre el mundo 3D y el lenguaje
Para entrenar los modelos, el equipo necesitaba recopilar un número suficiente de pares de datos en 3D y lenguaje natural, ya que estos conjuntos de datos son limitados en comparación con los pares de imágenes y texto disponibles en la web. Por lo tanto, el equipo desarrolló técnicas de estimulación para el ChatGPT con el fin de generar diferentes descripciones y diálogos en 3D.
El resultado es un conjunto de datos con más de 300,000 ejemplos de texto en 3D, que abarcan tareas como etiquetado en 3D, respuestas a preguntas visuales, descomposición de tareas y navegación. Por ejemplo, se le pidió al ChatGPT que describiera una escena de una habitación en 3D haciendo preguntas sobre objetos visibles desde diferentes ángulos.

La equipo conecta descripciones de texto a puntos en el espacio 3D
A continuación, desarrollaron extractores de características en 3D para convertir los datos en 3D en un formato compatible con modelos de lenguaje pre-entrenados en visión 2D, como BLIP-2 y Flamingo.
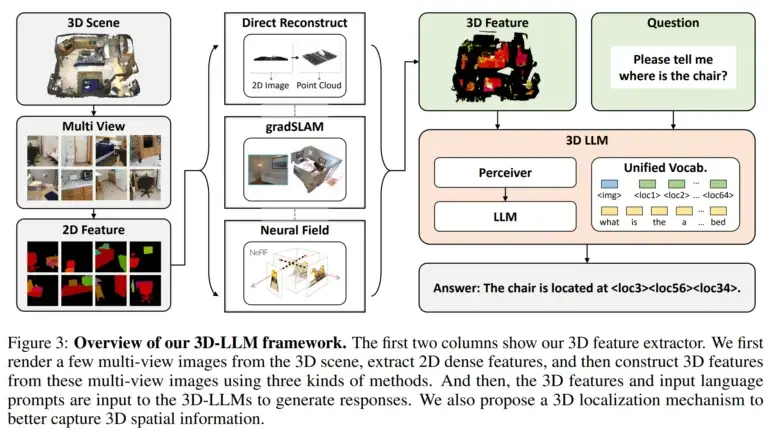
Además, los investigadores utilizaron un mecanismo de localización en 3D que permitió que los modelos capturaran información espacial al asociar descripciones de texto con coordenadas en 3D. Esto también facilitó el uso de modelos como BLIP-2 para entrenar eficientemente los 3D LLMs a entender escenas en 3D.
Las pruebas con el modelo de lenguaje 3D mostraron resultados prometedores
Los experimentos demostraron que los modelos de lenguaje 3D fueron capaces de generar descripciones en lenguaje natural de escenas en 3D, llevar a cabo diálogos conscientes de 3D, descomponer tareas complejas en acciones en 3D y relacionar el lenguaje con ubicaciones espaciales. Esto demuestra el potencial de la IA para desarrollar una percepción más similar a la humana de entornos en 3D, incorporando capacidades de razonamiento espacial, según los investigadores.
Los investigadores planean extender los modelos a otras modalidades de datos, como el sonido, y entrenarlos para realizar tareas adicionales. También afirman que el objetivo es aplicar estos avances a asistentes de IA incorporados que puedan interactuar de manera inteligente con entornos en 3D. Con contenido de The Decoder.
